
FreeRTOS
文档:
https://rtos.100ask.net/zh/FreeRTOS/DShanMCU-F103/chapter6.html
项目介绍
裸机:
freerots:

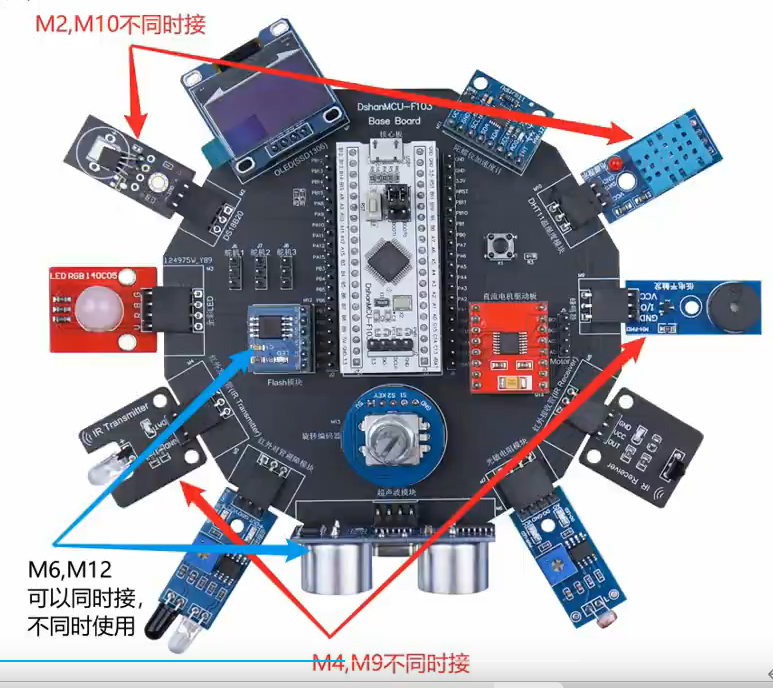
涉及到三个项目:音乐播放 打砖块游戏,汽车游戏

2-2,2-3讲自己创建一个freertos工程
从3.1开始正式讲freertos
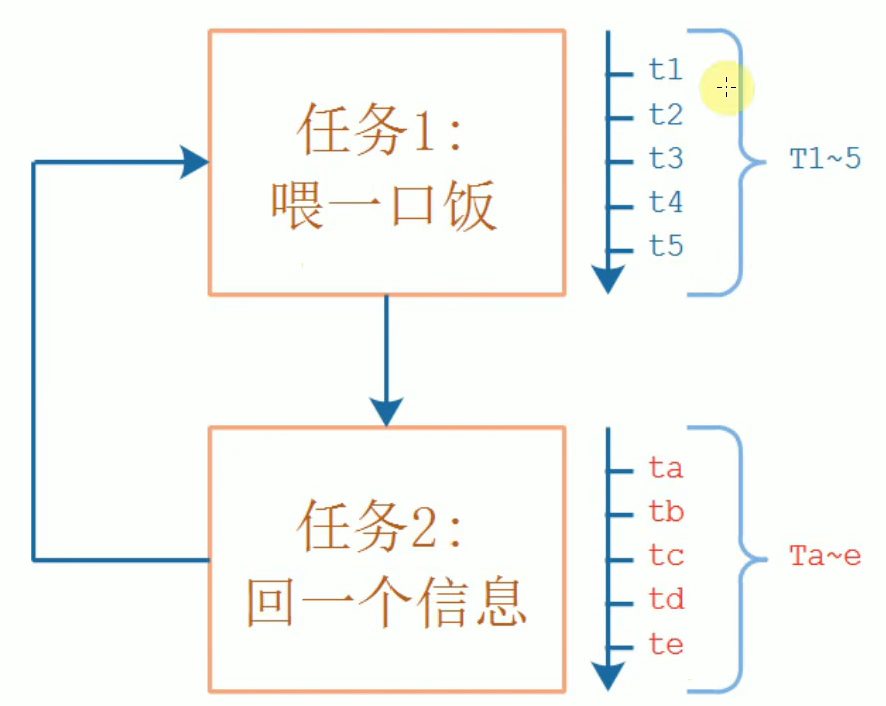
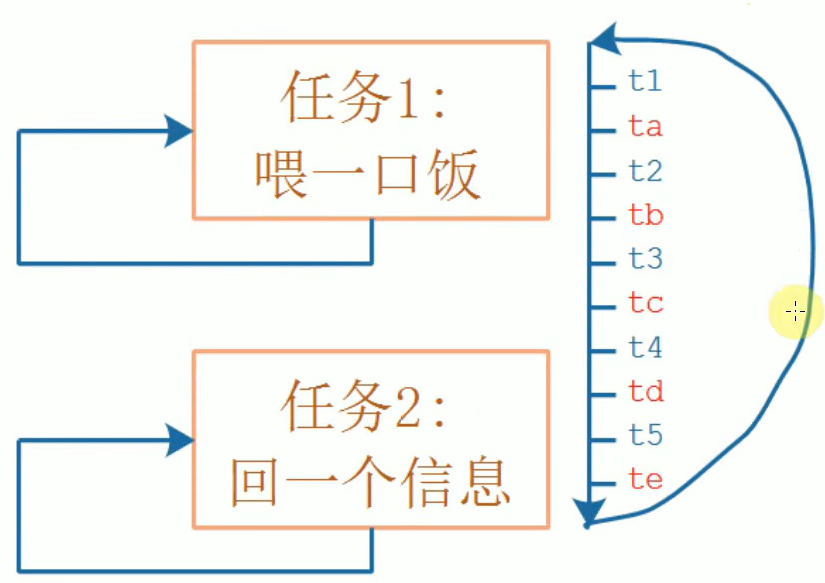
创建第一个多任务程序
不同的嵌入式操作系统,如freertos,rt-thread,它们对相同的一个操作的函数名称不同,为了统一起来,增加了一个接口层cmsis_os ,我们直接用这个文件的函数就行了,这个函数会根据不同的操作系统进行选择相应的代码,这样你写出来的代码既可以运行在freertos也可以在rt-thread上。
创建工程时默认生成的任务,osThreadNew为cmsis_os中定义的函数

我们要等会要用的是freertos的原生代码去创建任务
在此创建自己的任务函数
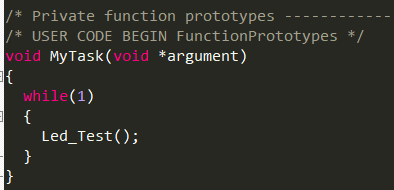
在此处创建自己的任务

ARM架构简明教程_硬件架构与汇编指令
我们去创建一个任务的时候,为什么要指定栈,你理解了栈之后,才能深入理解RTOS的本质,要想理解栈,你得对处理器的架构有所了解
ARM架构
CPU(计算), 内存(RAM) ,FLSAH
RISC
ARM芯片属于精简指令集计算机(RISC:Reduced Instruction Set Computing),它所用的指令比较简单,有如下特点:
① 对内存只有读、写指令
② 对于数据的运算是在CPU内部实现
③ 使用RISC指令的CPU复杂度小一点,易于设计
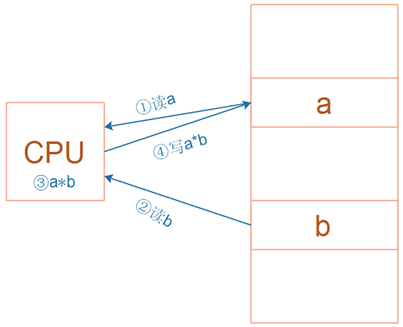
对于上图所示的乘法运算a = a * b,
在RISC中要使用4条汇编指令:
① 读内存a
② 读内存b
③ 计算a*b
④ 把结果写入内存
提出问题
问题:在CPU内部,用什么来保存a、b、a*b ?
CPU内部寄存器
CPU, 内存 , FLASH
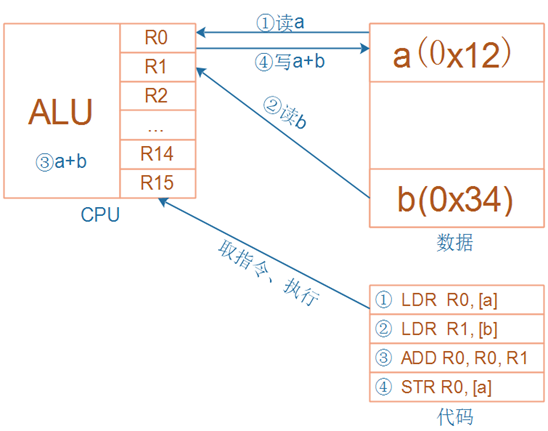
无论是cortex-M3/M4,
还是cortex-A7,
CPU内部都有R0、R1、……、R15寄存器;
它们可以用来“暂存”数据。
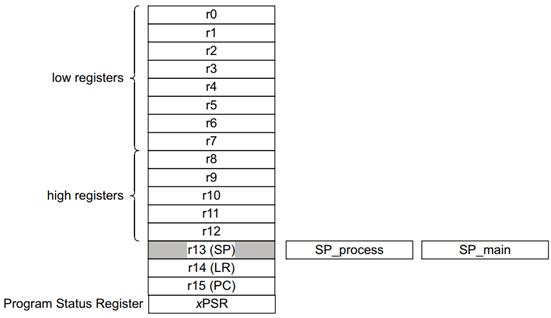
对于R13、R14、R15,还另有用途:
R13:别名SP(Stack Pointer),栈指针
R14:别名LR(Link Register),用来保存返回地址
R15:别名PC(Program Counter),程序计数器,表示当前指令地址,写入新值即可跳转(往PC寄存器写入某个值,它就会跳过去执行对应的代码)
汇编
汇编指令
读内存:Load
1
2示例
LDR R0, [R1, #4] ; 读地址"R1+4", 得到的4字节数据存入R0写内存:Stroe
1
2示例
STR R0, [R1, #4] ; 把R0的4字节数据写入地址"R1+4"加减
1
2
3
4ADD R0, R1, R2 ; R0=R1+R2
ADD R0, R0, #1 ; R0=R0+1
SUB R0, R1, R2 ; R0=R1-R2
SUB R0, R0, #1 ; R0=R0-1比较
1
CMP R0, R1 ; 结果保存在PSR(程序状态寄存器)
跳转 (调用函数)
1
2B main ; Branch, 直接跳转
BL main ; Branch and Link, 先把返回地址保存在LR寄存器里再跳转 (1.LR=返回地址(下一条指令),2.PC=调用函数的地址。 往PC寄存器写入某个值,它就会跳过去执行对应的代码)局部变量都保存在栈里。
C函数的反汇编
C函数:
1 | int add(volatile int a, volatile int b) |
让Keil生成反汇编:(通过反汇编码,更好的理解栈)

为例方便复制,制作反汇编的指令如下:
1 | fromelf --text -a -c --output=xxx.dis xxx.axf |
C函数add的反汇编代码如下:
1 | i.add |
堆和栈
堆(heap)
所谓堆,就是一块空闲的内存,你也可以管理这块内存,从其中取出(malloc)一部分,用完之后再把它释放(free)回去。
堆,heap,就是一块空闲的内存,需要提供管理函数
- malloc:从堆里划出一块空间给程序使用
- free:用完后,再把它标记为”空闲”的,可以再次使用
栈 (stack)
栈是RTOS的基础,也是一块内存空间,CPU的SP寄存器指向它,可以用于函数调用,局部变量,多任务系统里保存现场,每一个任务都会有自己的栈。栈在内存(RAM)中。
栈,stack,函数调用时局部变量保存在栈中,当前程序的环境也是保存在栈中
- 可以从堆中分配一块空间用作栈
提问1:LR被覆盖了,怎么办?
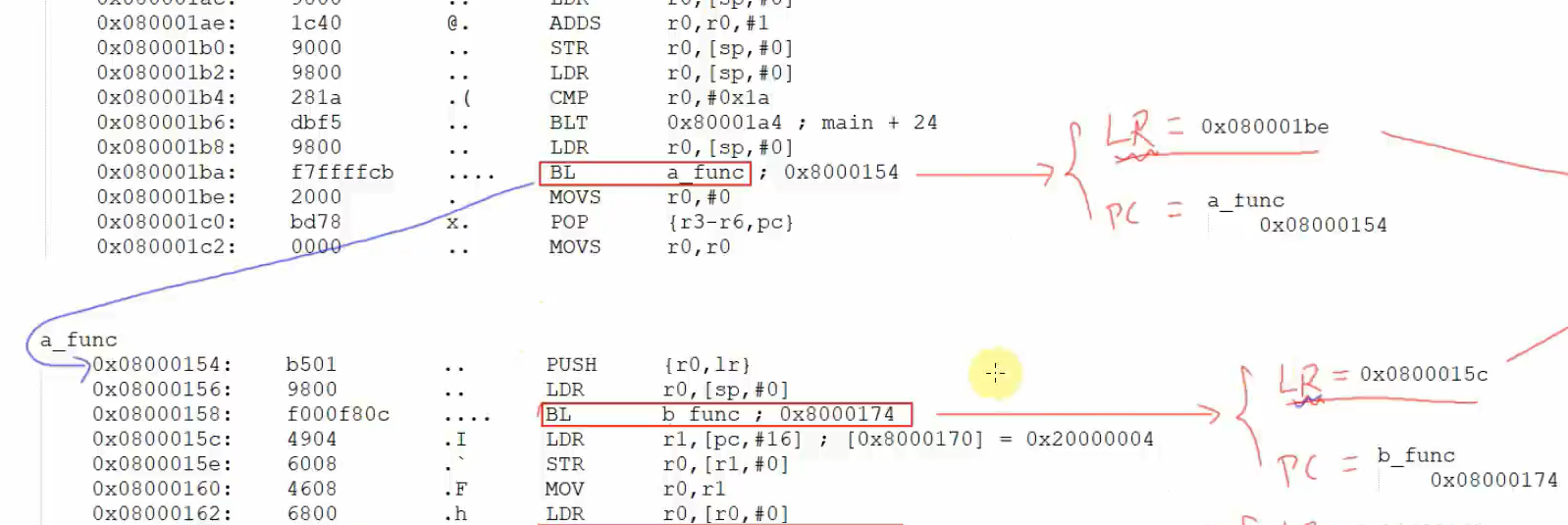
答:在C入口,会首先划分出自己的栈,保存LR进栈里,保存局部变量,在每个函数的入口都会保存LR 以及必要的寄存器,以防后面操作将其覆盖
例:
1 | int g_cnt=0; |
上面的代码里,进入main函数后先调用a函数,然后在a函数中分别调用b,c函数
下面是对应的反汇编代码
第9行 BL a_func
1 | i.main |
a_func: 调用了b_func ,c_func
1 | a_func |
b_func
1 | b_func |
c_func
1 | c_func |
对应的栈区域以及里面的内容

提问2:局部变量在栈中是如何分配的?
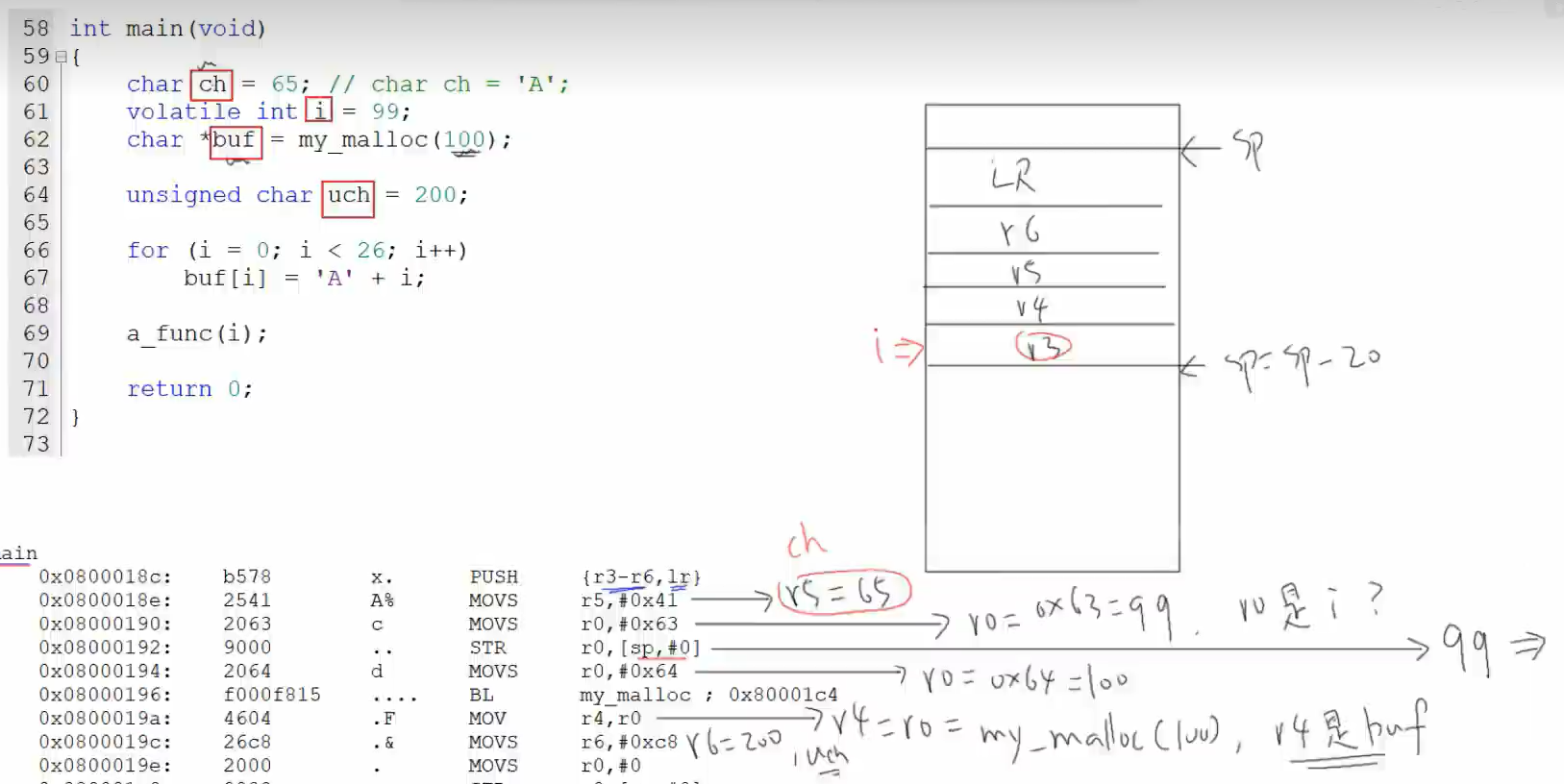
变量ch,buf,uch这三个变量没加volatile,它们优先使用寄存器来表示(随着变量越来越多,寄存器不够用,就在栈里分配空间);变量i用了volatile,它在栈里给你分配了空间
提问3:为什么每个RTOS任务都有自己的栈?
每个任务都有自己的调用关系,自己的局部变量和现场
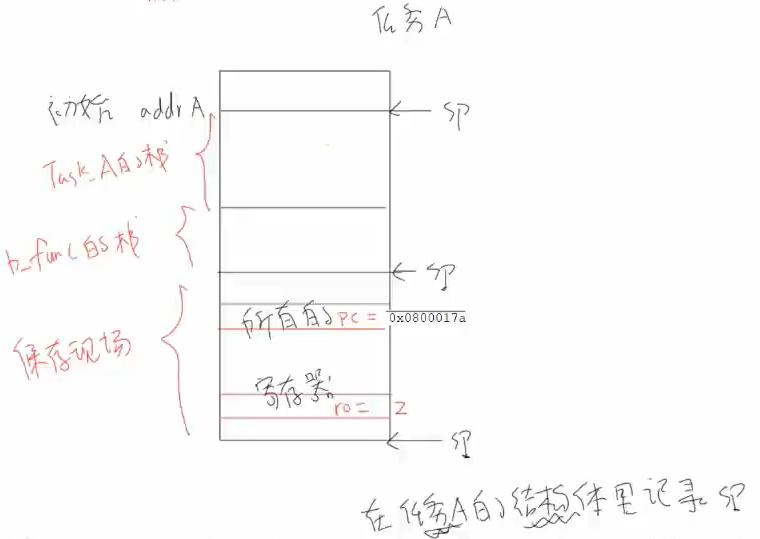
恢复现场:找到任务的结构体,得到任务的栈,SP地址,将寄存器的值从栈里恢复到CPU里面
FreeRTOS源码结构概述
FreeRTOS目录结构
使用STM32CubeMX创建的FreeRTOS工程中,FreeRTOS相关的源码如下:

主要涉及2个目录:
- Core
- Inc目录下的FreeRTOSConfig.h是配置文件
- Src目录下的freertos.c是STM32CubeMX创建的默认任务
- Middlewares\Third_Party\FreeRTOS\Source
- 根目录下是核心文件,这些文件是通用的
- portable目录下是移植时需要实现的文件
- 目录名为:[compiler]/[architecture]
- 比如:RVDS/ARM_CM3,这表示cortexM3架构在RVDS工具上的移植文件
7.2核心文件 FreeRTOS的最核心文件只有2个:
FreeRTOS/Source/tasks.c
FreeRTOS/Source/list.c
其他文件的作用也一起列表如下:
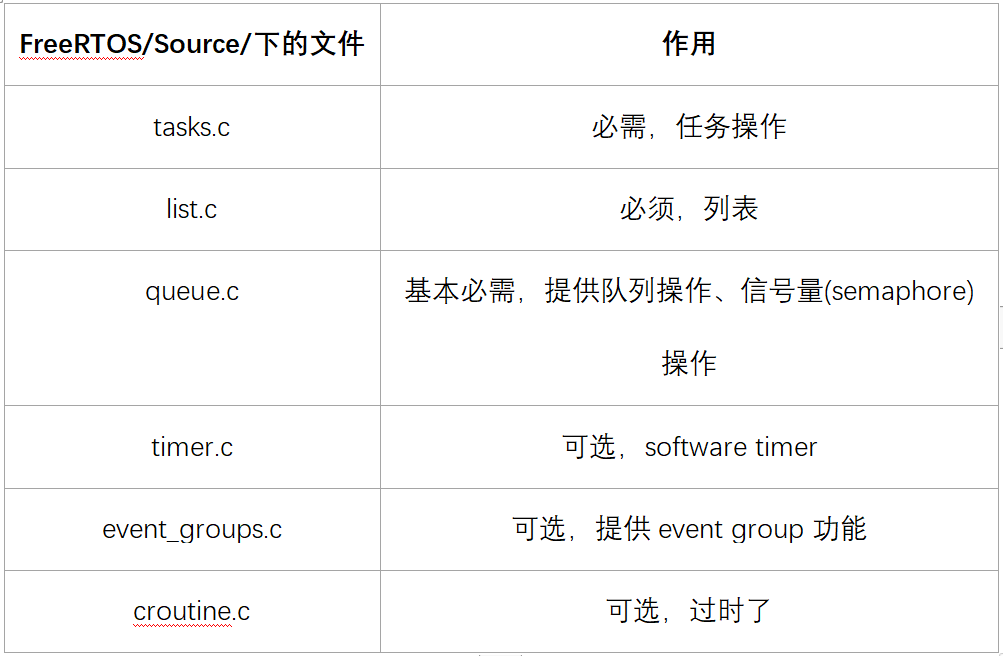
移植时涉及的文件
移植FreeRTOS时涉及的文件放在 FreeRTOS/Source/portable/[compiler]/[architecture] 目录下,比如:RVDS/ARM_CM3,这表示cortexM3架构在RVDS或Keil工具上的移植文件。 里面有2个文件:
- port.c
- portmacro.h
头文件相关
头文件目录
FreeRTOS需要3个头文件目录:
- FreeRTOS本身的头文件:
Middlewares\Third_Party\FreeRTOS\Source\include
- 移植时用到的头文件:
Middlewares\Third_Party\FreeRTOS\Source\portable[compiler][architecture]
- 含有配置文件FreeRTOSConfig.h的目录:Core\Inc
头文件
列表如下:

内存管理
文件在Middlewares\Third_Party\FreeRTOS\Source\portable\MemMang下,它也是放在“portable”目录下,表示你可以提供自己的函数。
源码中默认提供了5个文件,对应内存管理的5种方法。
后续章节会详细讲解。
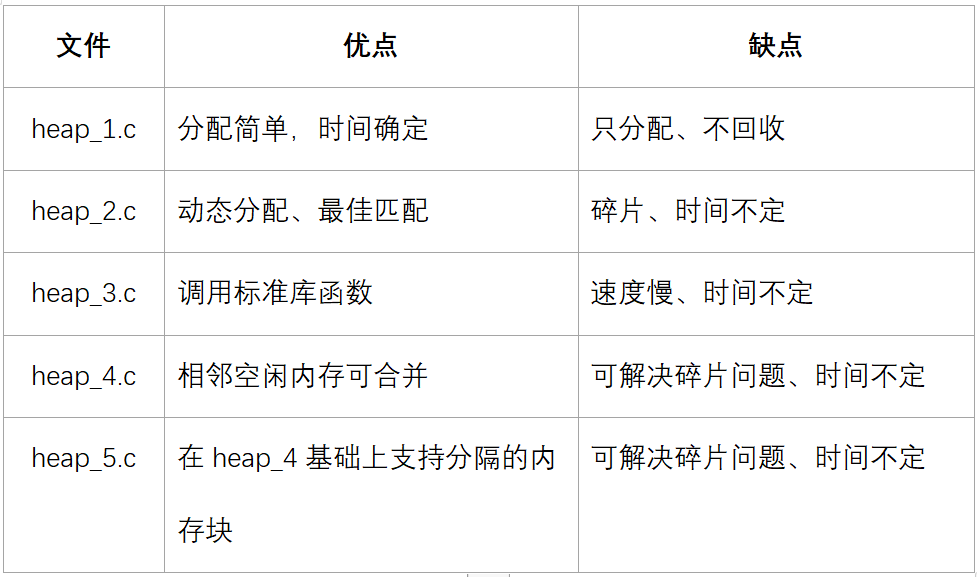
入口函数
在Core\Src\main.c的main函数里,初始化了FreeRTOS环境、创建了任务,然后启动调度器。源码如下:
1 | /* Init scheduler */ |
数据类型和编程规范
数据类型
每个移植的版本都含有自己的portmacro.h头文件,里面定义了2个数据类型:
- TickType_t:
- FreeRTOS配置了一个周期性的时钟中断:Tick Interrupt
- 每发生一次中断,中断次数累加,这被称为tick count
- tick count这个变量的类型就是TickType_t
- TickType_t可以是16位的,也可以是32位的
- FreeRTOSConfig.h中定义configUSE_16_BIT_TICKS时,TickType_t就是uint16_t
- 否则TickType_t就是uint32_t
- 对于32位架构,建议把TickType_t配置为uint32_t
- BaseType_t:
- 这是该架构最高效的数据类型
- 32位架构中,它就是uint32_t
- 16位架构中,它就是uint16_t
- 8位架构中,它就是uint8_t
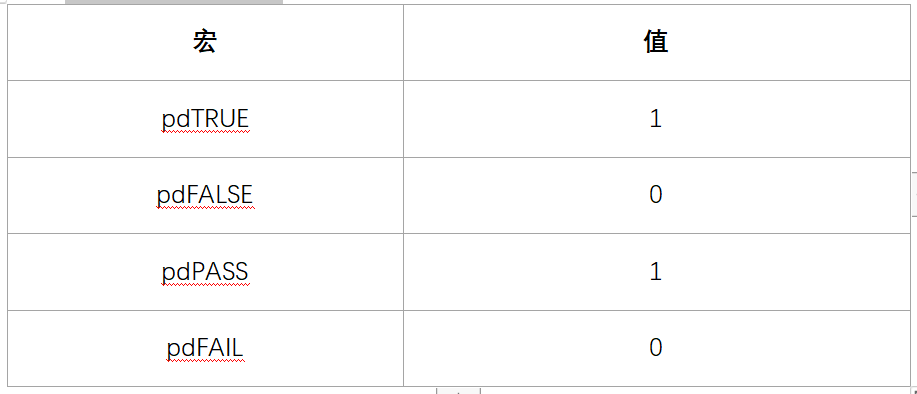
- BaseType_t通常用作简单的返回值的类型,还有逻辑值,比如pdTRUE/pdFALSE
- 在 RTOS 中,函数的返回值不仅仅局限于0、1和-1这样的简单逻辑值,它还可能表示优先级、任务句柄等多种信息,这些信息在某些情况下可能需要用到较大的数据宽度。因此,使用
BaseType_t可以灵活适应各种情况。
变量名
变量名有前缀:
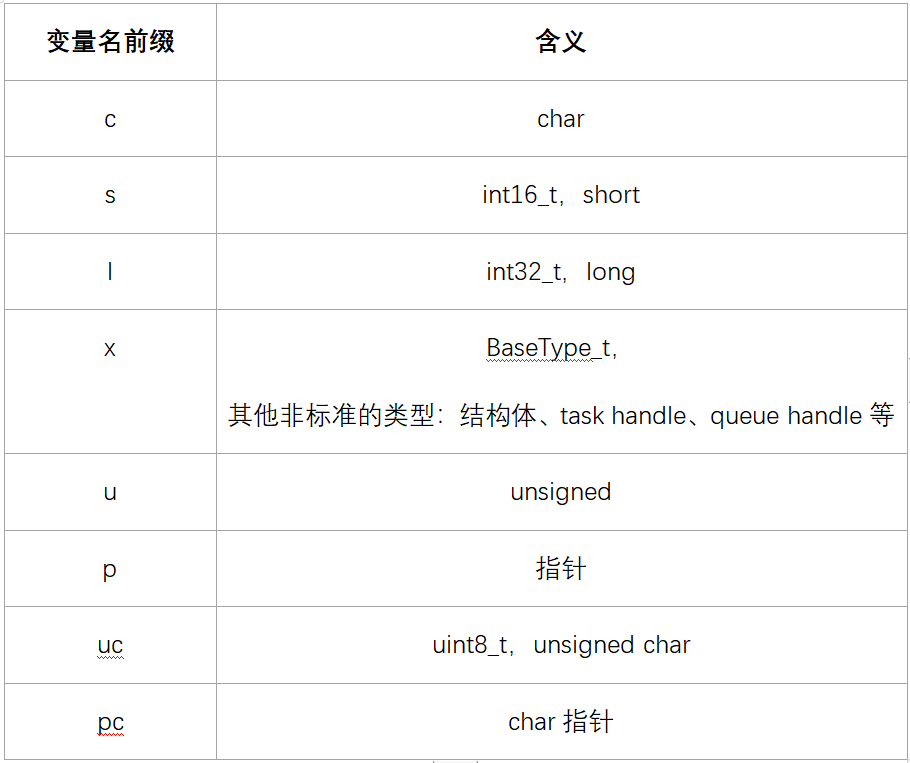
函数名
函数名的前缀有2部分:返回值类型、在哪个文件定义。
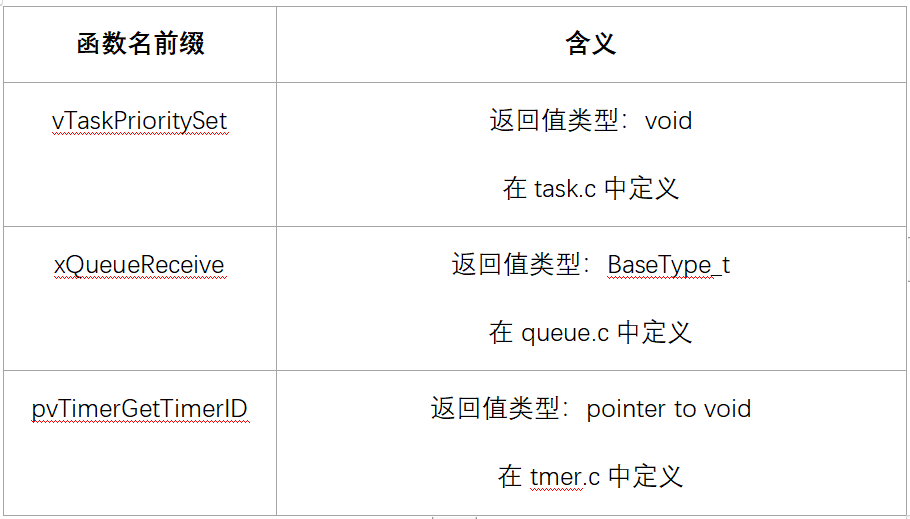
宏的名
宏的名字是大小,可以添加小写的前缀。前缀是用来表示:宏在哪个文件中定义。
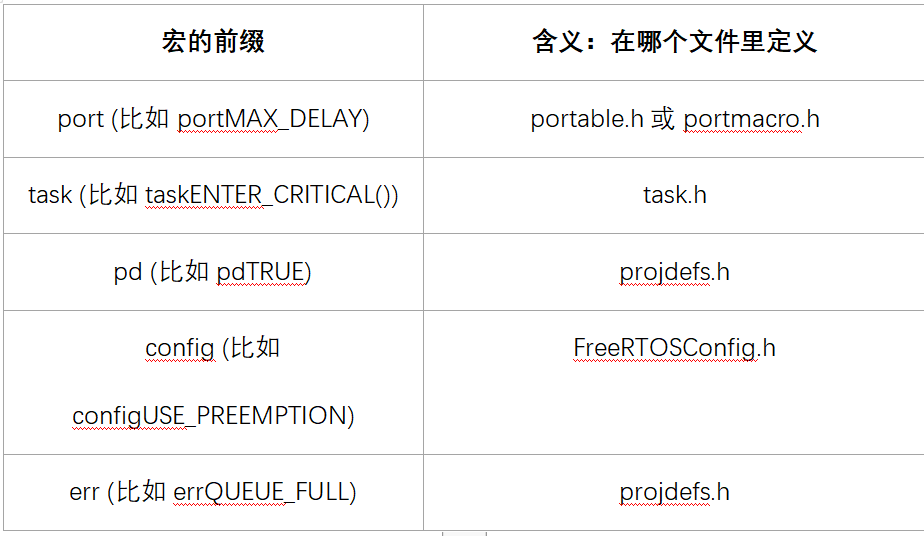
通用的宏定义如下:
内存分配(栈)
为了让FreeRTOS更容易使用,这些内核对象一般都是动态分配:用到时分配,不使用时释放。使用内存的动态管理功能,简化了程序设计:不再需要小心翼翼地提前规划各类对象,简化API函数的涉及,甚至可以减少内存的使用。
注意:我们经常”堆栈”混合着说,其实它们不是同一个东西:
堆,heap,就是一块空闲的内存,需要提供管理函数
- malloc:从堆里划出一块空间给程序使用
- free:用完后,再把它标记为”空闲”的,可以再次使用
栈,stack,函数调用时局部变量保存在栈中,当前程序的环境也是保存在栈中
- 可以从堆中分配一块空间用作栈

FreeRTOS中内存管理的接口函数为:pvPortMalloc 、vPortFree,对应于C库的malloc、free。
cubemx中关于栈的配置:


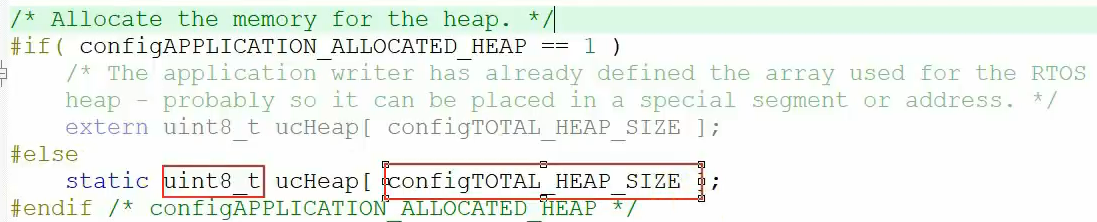
用一个ucHeap数组来表示堆
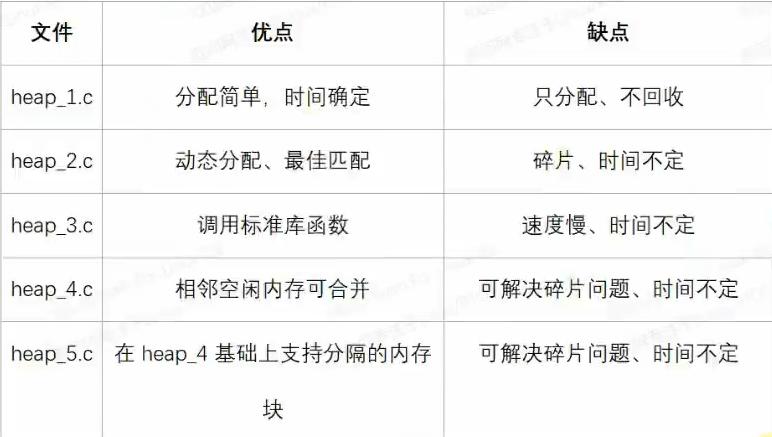
heap4会合并相邻的空闲buffer,所以可解决碎片问题,一般都有heap4,如果有多块内存用heap5

比如你想知道你分配的3072字节的栈空间够不够用,你可以让程序跑一段时间,然后调用这个函数来看看,如果它接近个位数或十位数,则容量很危险,我们要把栈空间分配大一点
任务管理
三要素:函数,栈,优先级
TCB:任务控制块(任务结构体)
任务控制块(TCB)通常包含了以下内容:
- 任务堆栈指针:指向任务堆栈的顶部。
- 任务优先级:表示该任务的优先级等级。
- 任务状态:如运行、就绪、阻塞、挂起等。
- 延时计数器和超时时间:用于处理任务延时和超时唤醒。
- 其他可能的信息:如任务入口函数地址、任务ID或名称等。
当创建一个新任务时,FreeRTOS会为该任务分配并初始化一个TCB,并返回这个TCB的指针作为任务句柄。这样,在后续操作中,通过任务句柄就能间接访问和修改对应任务的所有信息。
创建任务
a.动态分配
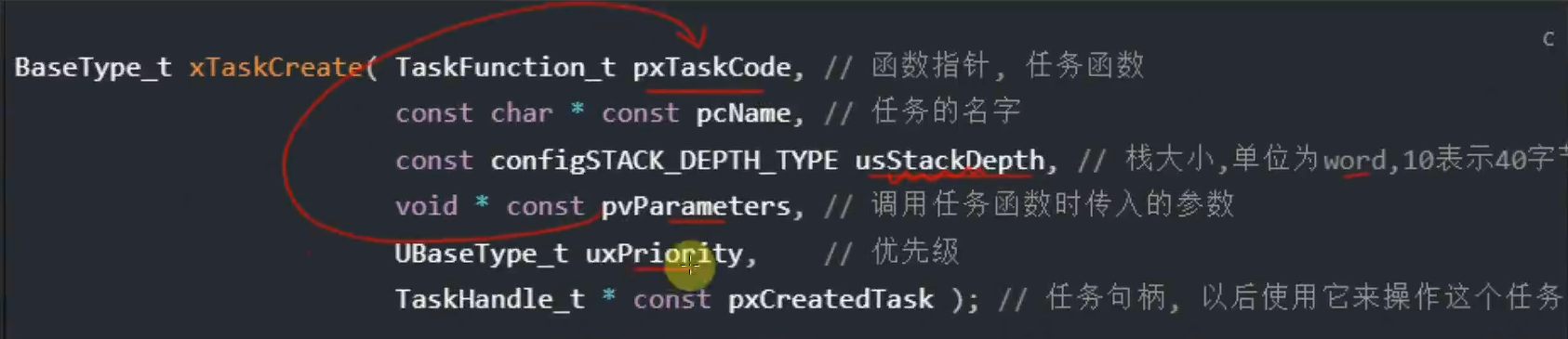
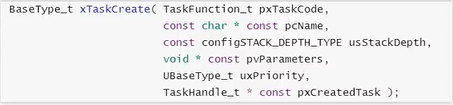
1 | BaseType_t xTaskCreate( TaskFunction_t pxTaskCode, // 函数指针, 任务函数 |
pxTaskCode: 函数指针,指向我们的任务函数,在这里写我们自己写的任务函数的函数名。
pcName:任务名,没啥用,自己随便取,eg: “LightTask”
usStackDepth: 栈大小,单位为字(word),一个字的大小取决于计算机处理器的位数。在大多数现代计算机中,一个字的大小通常是32位或64位,也就是说,一个字的大小通常是4个字节或8个字节。
pvParameters: 调用任务函数时传入的参数,即pxTaskCode的参数,如果它没有参数,直接写NULL就行
uxPriority:优先级范围:0~(configMAX_PRIORITIES – 1) 数值越小优先级越低, 如果传入过大的值,xTaskCreate会把它调整为(configMAX_PRIORITIES – 1)
pxCreatedTask:用于保存 xTaskCreate 的输出结果,即任务的句柄(task handle)。如果以后需要对该任务进行操作,如修改优先级,则需要使用此句柄。如果不需要使用该句柄,可以传入 NULL。
返回值:成功时返回 pdPASS,失败时返回 errCOULD_NOT_ALLOCATE_REQUIRED_MEMORY ,BaseType_t通常用作简单的返回值的类型、
实例:
1 | TaskHandle_t xSoundTaskHandle;//任务句柄 |
b.静态分配
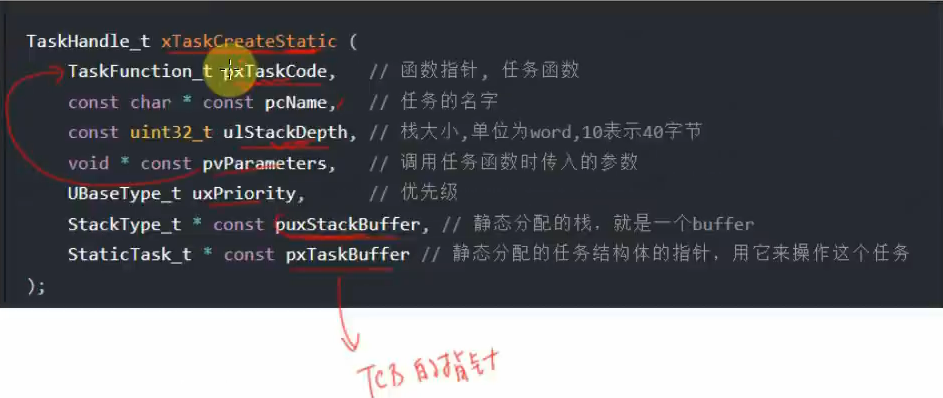
1 | TaskHandle_t xTaskCreateStatic ( |
pxTaskCode: 函数指针,指向我们的任务函数,在这里写我们自己写的任务函数的函数名。
pcName:任务名,没啥用,自己随便取,eg: “LightTask”
ulStackDepth: 栈大小,值是你提前分配的栈(puxStackBuffer)所对应的大小,单位为字;ulStackDepth 在FreeRTOS中的单位通常根据具体平台和编译器的字长来确定。在32位架构下,一个“字”通常是32位,在16位架构下,则是16位。因此,当提到任务堆栈深度时,如果没有特别说明,可以根据目标处理器架构默认为该架构下的“字”长度。例如,在32位架构中,如果 ulStackDepth 设置为100,则意味着为任务分配了400字节(100 * 4)的堆栈空间。
pvParameters: 调用任务函数时传入的参数,即pxTaskCode的参数,如果它没有参数,直接写NULL就行
uxPriority:优先级范围:0~(configMAX_PRIORITIES – 1) 数值越小优先级越低, 如果传入过大的值,xTaskCreate会把它调整为(configMAX_PRIORITIES – 1)
puxStackBuffer:一个指向预分配的静态任务堆栈缓冲区的指针。这意味着开发者需要自己管理内存,而不是由系统动态分配。比如可以传入一个数组, 它的大小是usStackDepth*4。
pxTaskBuffer: 指向一个静态任务控制块(TCB)结构体的指针(StaticTask_t 是一个结构体类型,它就是TCB))。同样,这里要求开发者预先分配好存储TCB的空间。
返回值:成功时返回 pdPASS,失败时返回 errCOULD_NOT_ALLOCATE_REQUIRED_MEMORY ,BaseType_t通常用作简单的返回值的类型
实例:
1 | static StackType_t g_pucStackOfLightTask[128*4?]; |
疑惑:ulStackDepth和puxStackBuffer值的关系?
估算栈的大小
确定栈的大小并不容易,通常是根据估计来设定。精确的办法是查看反汇编代码。
栈里面保存的东西:
1.返回地址LR寄存器,其它寄存器:取决于函数调用深度,一般选取最复杂的调用关系来计算
理论上最多要保存的寄存器(9个):
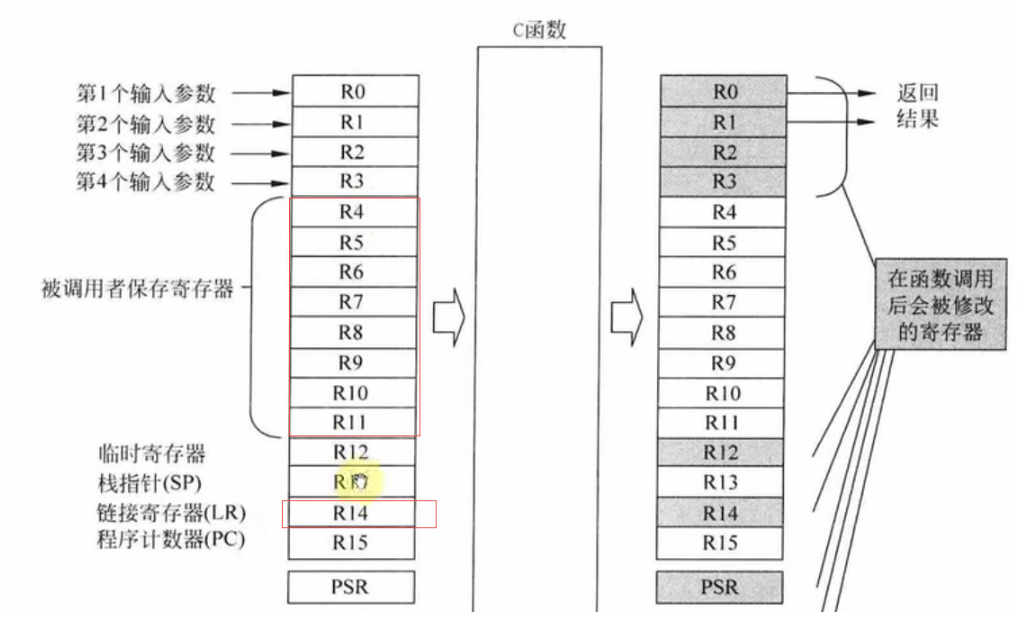
可以通过汇编代码查看函数保存的寄存器:

eg: A->B->C->D->E 5级调用*(被调用者寄存器R4~R11 共8个,LR寄存器,总计9个)
5x9x4=180
我们可以得出:调用深度越深,需要的栈越大。
但是用到栈最大的情况不一定是在最深的调用关系这里出现,可能一个函数里定义了一个巨大的局部变量,你得去看你的代码,找到使用局部变量最多的函数
2.局部变量:取决于你的代码,比如你用了一个char buf[1000]
3.现场:16x4 =64 (16个寄存器)
通过1,2,3 你就可以大概估计出你这个程序用到的栈最大有多少,当然最精确的就是去看反汇编。
实例估计:

4层调用:4x9x4=144
局部变量: MUSI_Analysis()函数里有两个局部变量,4个字节,PassiveBuzzer_Set_Freq_Duty函数里有一个结构体,28字节。共计32字节
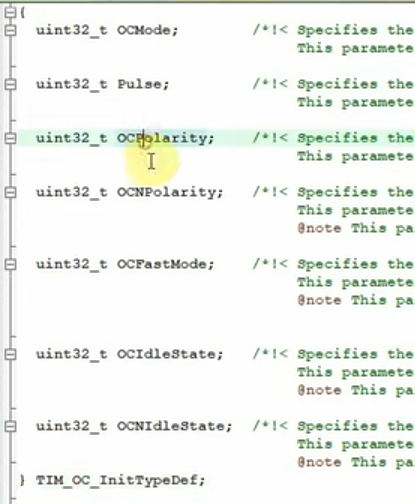
现场:64字节
用到的栈约等于:144+32+64=250字节
我们提供的栈是128字,即128*4字节>250,所以粗略估算是够用的。

精确计算栈的大小以后再说。
创建任务_使用任务参数
创建两个任务,使用同一个函数,在LCD上打印不一样的信息
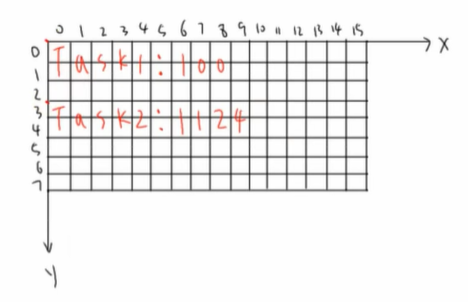
1 | struct TaskPrintInfo |
提问:如何互斥地访问LCD?使用全局变量,大概率可以,但不是万无一失
提问:为何是后面创建的task3先运行?
删除任务
用遥控器删除任务
功能为:
当监测到遥控器的播放按键按下时,创建音乐播放任务
当监测到遥控器的Power案件按下后,删除音乐播放任务
删除任务时使用的函数如下:
1 | void vTaskDelete( TaskHandle_t xTaskToDelete ); |
参数说明:
| 参数 | 描述 |
|---|---|
| pvTaskCode | 任务句柄,使用xTaskCreate创建任务时可以得到一个句柄。 也可传入NULL,这表示删除自己。 |
怎么删除任务?举个不好的例子:
- 自杀:vTaskDelete(NULL)
- 被杀:别的任务执行vTaskDelete(pvTaskCode),pvTaskCode是自己的句柄
- 杀人:执行vTaskDelete(pvTaskCode),pvTaskCode是别的任务的句柄
一句话就是你要删除哪个任务,就传入这个任务的句柄到该函数s
提问:频繁的创建,删除任务,好吗?有什么坏处?
频繁的动态分配内存,释放内存,容易产生内存碎片,多次执行之后可能就分配不到内存了
不能简单的删除一个任务,然后就不管一些后续的清理工作了,要初始化到原来的状态。实际上一般删除任务用的较少,可以直接让任务读取这遥控器,让它自己去停止,做一些清除工作。
优先级与阻塞
前言:
在之前的程序里,播放音乐的时候效果都比较差,会慢半拍,比较卡顿,只要我们把其它任务注释掉就比较顺畅。
提高音乐播放器的优先级,使用vTaskDelay进行延时,就可以改善播放器效果,同时让其它任务不受影响s。
首先,我们让音乐播放的优先级+1
1 | ret = xTaskCreate(PlayMusic, "SoundTask", 128, NULL, osPriorityNormal+1, &xSoundTaskHandle); |
现象:其他任务都不动了,而且按power键删除不了播放音乐任务
这是因为我们创建了一个高优先级的任务,它一直在运行,独占CPU
我们要修改这个高优先级的任务,让它在运行过程中主动放弃CPU资源,不再参与调度
将mdelay替换为vTaskDelay,在延时的过程中它不会参与调度。
内部机制:
(重要)任务状态与调度理论
eg:实现音乐的暂停与继续播放
任务状态
Running运行状态
Ready就绪状态:当创建一个任务后,它就处于就绪状态
Blocked阻塞状态(等待某些event) : 一个处于running状态的函数,当用vTaskDelay时,变成Blocked阻塞状态
Suspend暂停状态:可以自己调用(必处于running状态)vTaskSuspend()函数,把自己放入暂停状态,或者由别的任务来调用该函数,把你放入暂停状态,别人处于running状态,你处于ready或blocked状态
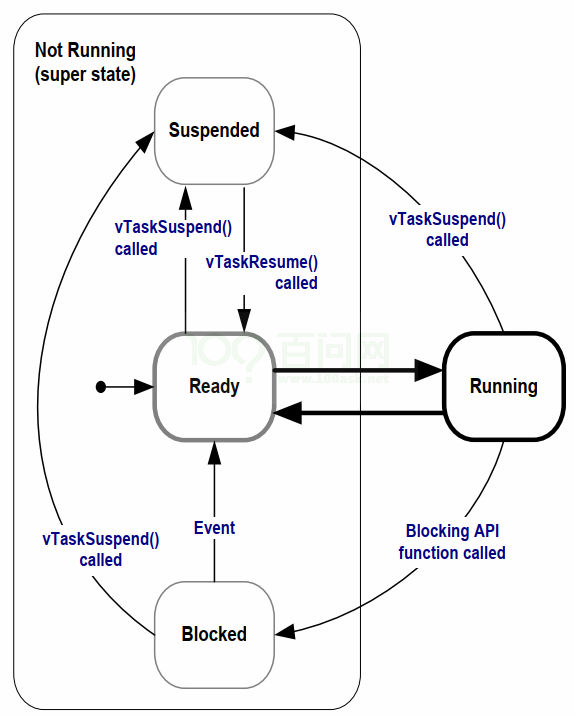
任务管理与调度机制
P22 这节是很重要的理论介绍,好好体会
调度:
1.相同优先级的任务轮流运行。
2.最高优先级的任务先运行。
高优先级的任务未执行完,低优先级的任务则无法运行
一旦高优先级的任务就绪,会马上运行,低优先级任务立刻停止
最高优先级的任务有多个,则它们轮流运行
记住RTOS的调度机制:就绪态的高优先级任务,一定会抢占低优先级的任务。高优先级的任务,不能总是运行。那么高优先级的任务,就应该“使用事件驱动”,比如发生了中断后,才唤醒高优先级的任务,它处理完数据后马上再次阻塞。现在就可以划分优先级了:第1种方法:按任务运行时间划分。比如能使用“事件驱动”的任务,可以设置它的优先级高一点,毕竟它平时大部分时间不运行,只有发生“某些事件(比如中断)”时才执行一会;需要长时间运行的任务,可以设置它的优先级低一点。第2种方法:按任务的紧急程度划分,比如不想丢失按键,那么按键的任务优先级就高;想GUI及时显示,GUI任务的优先级就高;但是要记住:高优先级的任务,一定不能长时间运行,否则其他低优先级的任务就无法运行了。
核心:链表
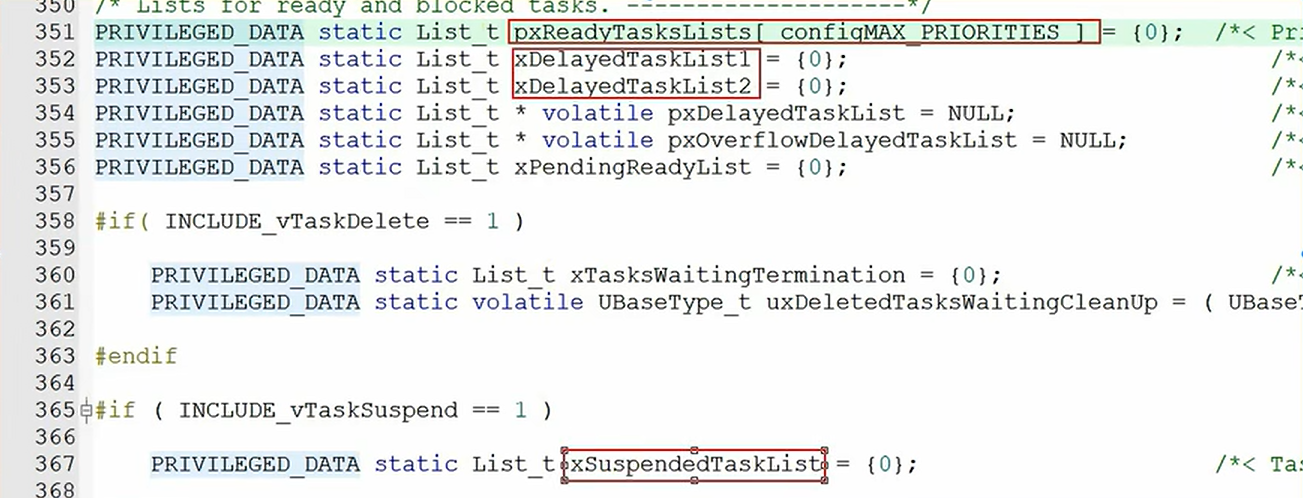
pxReadyTasksLists[N],存放优先级为N的处于Ready/Running状态的任务的TCB结构体

阅读代码会发现有一个全局指针pxCurrentTCB,每创建一个任务时该指针都指向它,启动调度器后,由于全局指针指向的是最后创建的这个任务,所以先从它这里执行(这就是06节后面创建的task3反而先运行的原因)
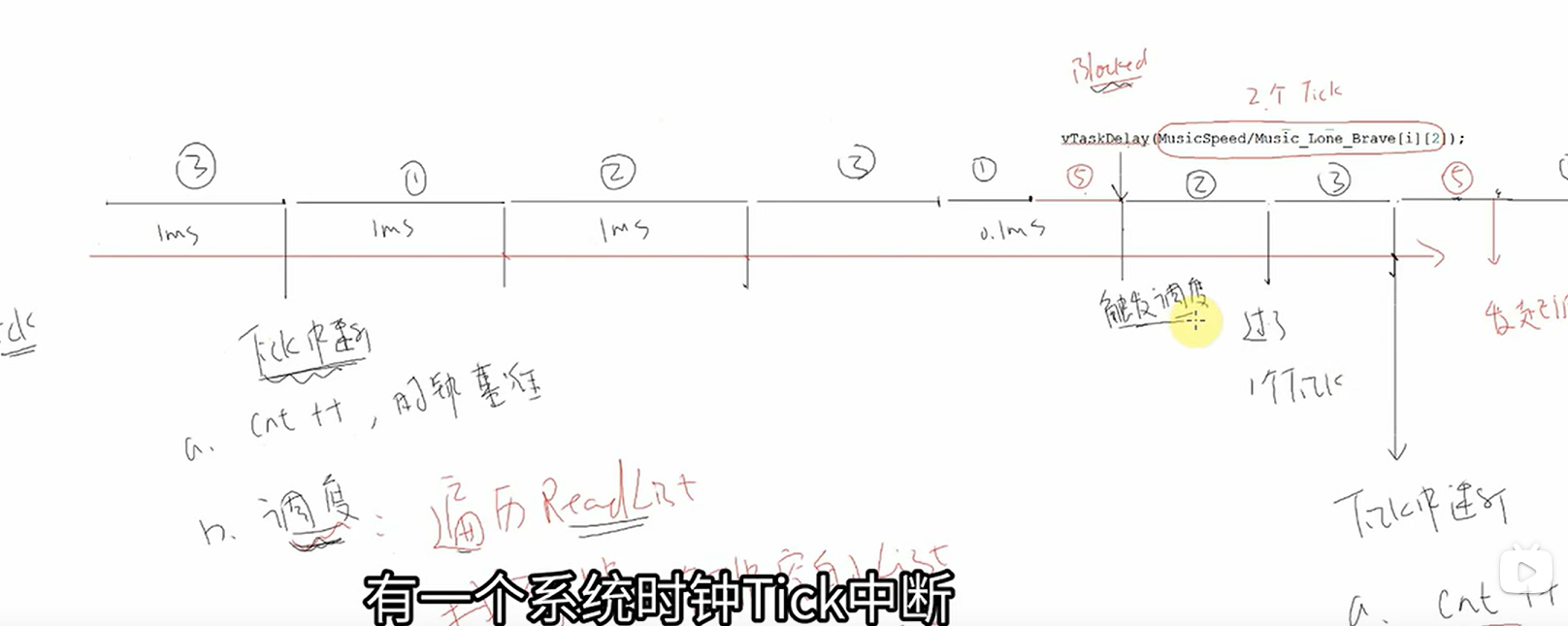
TICK中断:FREERTOS定义了一个时钟,TICK_RATE_HZ,cubemx中可以看到频率为1000,即1ms产生一次中断(Tick中断)
中断里会发生:
1.cnt++
2.判断DelayedTaskList里任务是否可以恢复,如果时间到了,就把它移到就绪链表,发起调度
3.发起调度
调度靠中断实现,关闭中断则也无法调度
发起调度:从高优先级到低来开始遍历链表数组,直到找到一个非空链表,找到下一个要运行的任务(当前指针所指向任务的下一个),然后运行该任务,直到1ms后再次发生TICK中断。
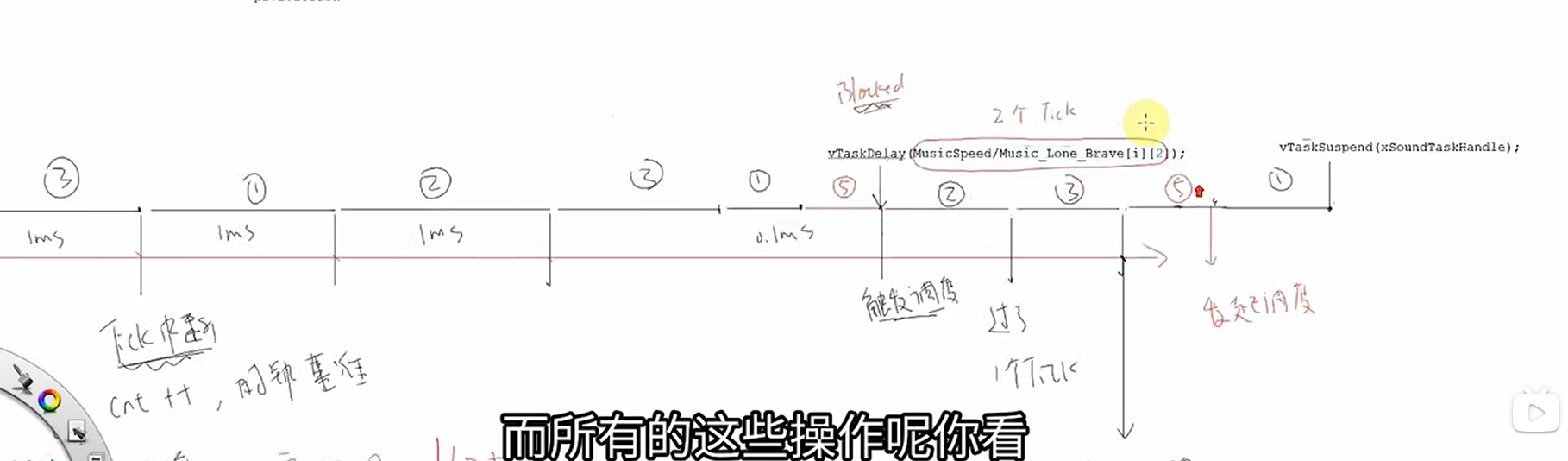
当StartfaultTask检测到播放按键被按下,创建了一个优先级更高的任务,则该任务会立即运行,当执行到vTaskDelay(2),则进入阻塞状态,阻塞2个TICK,它被从ReadyTaskList链表数组中删除,放到xDelayedTaskList链表数组中,主动放弃运行了,则触发调度,又去遍历链表数组,链表里有一个记录项index,会记录上一次运行的任务,则会从下一个任务来运行。当两个TICK到了,会判断DelayTaskList里任务是否可恢复,把他移出去,重新放入ReadList[25],然后开始发起调度。当被suspend挂起时,它会把你从ReadyTaskList链表里移出来,放到xSuspendedTaskList,当Resume时,则移出xSuspendTaskList,重新放到ReadyList
空闲任务
优先级最低,为0,要么处于就绪或者运行状态,永远不会阻塞。
空闲任务(Idle任务)的作用之一:释放被删除的任务的内存。
除了上述目的之外,为什么必须要有空闲任务?一个良好的程序,它的任务都是事件驱动的:平时大部分时间处于阻塞状态。有可能我们自己创建的所有任务都无法执行,但是调度器必须能找到一个可以运行的任务:所以,我们要提供空闲任务。在使用vTaskStartScheduler()函数来创建、启动调度器时,这个函数内部会创建空闲任务:
- 空闲任务优先级为0:它不能阻碍用户任务运行
- 空闲任务要么处于就绪态,要么处于运行态,永远不会阻塞
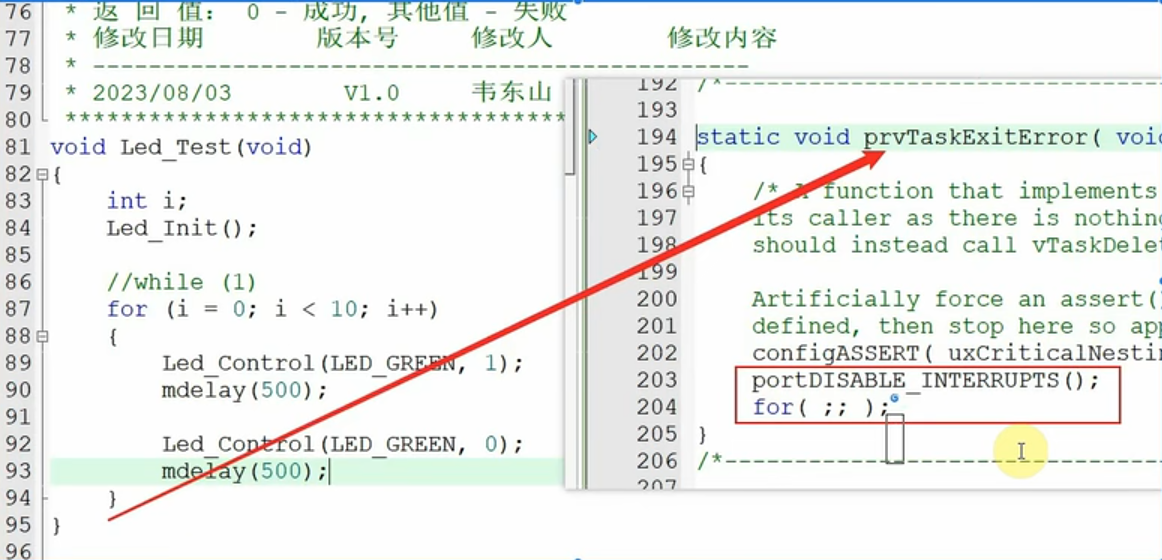
若Led_Test不是死循环,结束后不做处理直接退出的话,会直接进入到右侧错误函数,会关闭所有中断,进入死循环,所有任务都没办法继续执行。任务能够发生调度是依赖于TICK中断,现在中断都关了,则无法切换
任务结束后,要用vTaskDelete(NULL)删除任务
A杀B,由A给B收尸(清除工作,释放TCB结构体,释放栈) ;B自杀,空闲任务给它收尸
由于空闲任务优先级最低,若其他优先级的任务不主动放弃CPU,空闲任务无法执行,同时又有很多任务自杀,没人收尸,内存得不到释放,就会慢慢导致内存不足。
为了让空闲任务有机会运行,或者说是一种良好的编程习惯:
1.我们编写的任务函数,一般建议使用事件驱动,比如按下某个按键之后,它才会做某些事情,没有的话就阻塞。
2.延时函数,不要用死循环:mdelay替换为vTaskDelay,每个任务执行完用vTaskDelay(让当前任务不参与调度)进入阻塞状态(移出ReadyTaskList链表数组到xDelayTaskList),空闲任务才有机会运行。
钩子函数
我们可以添加一个空闲任务的钩子函数(Idle Task Hook Functions),空闲任务的循环每执行一次,就会调用一次钩子函数。钩子函数的作用有这些:
- 执行一些低优先级的、后台的、需要连续执行的函数 (比如可以打印出所有任务的栈信息)
- 测量系统的空闲时间:空闲任务能被执行就意味着所有的高优先级任务都停止了,所以测量空闲任务占据的时间,就可以算出处理器占用率。
- 让系统进入省电模式:空闲任务能被执行就意味着没有重要的事情要做,当然可以进入省电模式了。
- 空闲任务的钩子函数的限制:
- 不能导致空闲任务进入阻塞状态、暂停状态
- 如果你会使用vTaskDelete()来删除任务,那么钩子函数要非常高效地执行。如果空闲任务移植卡在钩子函数里的话,它就无法释放内存。
两个Delay函数
将mdelay替换为vTaskDelay,在延时的过程中任务不会参与调度,它不会阻塞让低优先级的任务有机会运行。
mdelay一直查询时间,不会使任务进入阻塞状态
vTaskDelay是把任务阻塞,这样低优先级的任务在它阻塞时也能运行。
有两个Delay函数:
- vTaskDelay:至少等待指定个数的Tick Interrupt才能变为就绪状态
- vTaskDelayUntil:等待到指定的绝对时刻,才能变为就绪态。
- 它们阻塞的单位都是TICK
这2个函数原型如下:
1 | void vTaskDelay( const TickType_t xTicksToDelay ); /* xTicksToDelay: 等待多少给Tick */ |
1 | pxPreviousWakeTime=xTaskGetTickCount();//获得启示时间 |
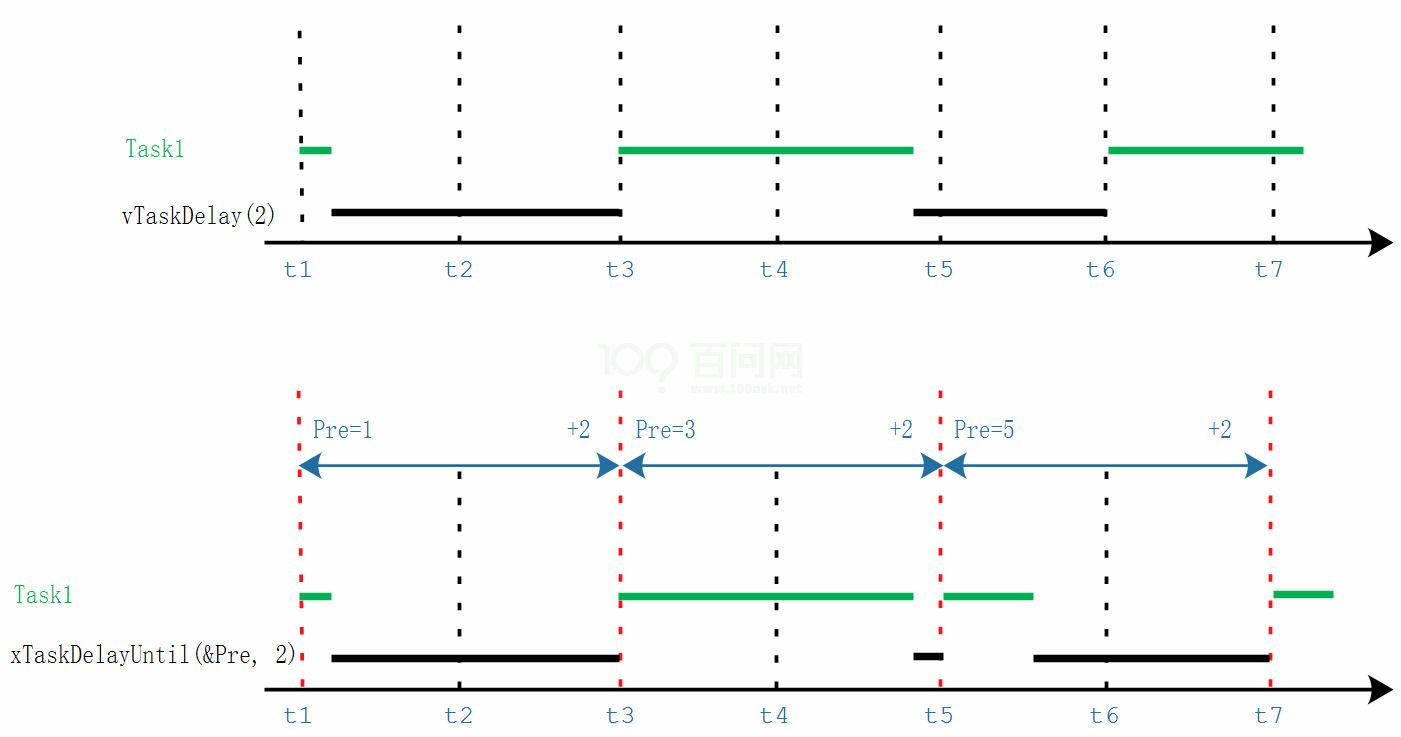
让每个任务启动时间的间隔是一个定值,周期性的启动运行,就要用vTaskDelayUntil
下面画图说明:
- 使用vTaskDelay(n)时,进入、退出vTaskDelay的时间间隔至少是n个Tick中断
- 使用xTaskDelayUntil(&Pre, n)时,前后两次退出xTaskDelayUntil的时间至少是n个Tick中断
- 退出xTaskDelayUntil时任务就进入的就绪状态,一般都能得到执行机会
- 所以可以使用xTaskDelayUntil来让任务周期性地运行
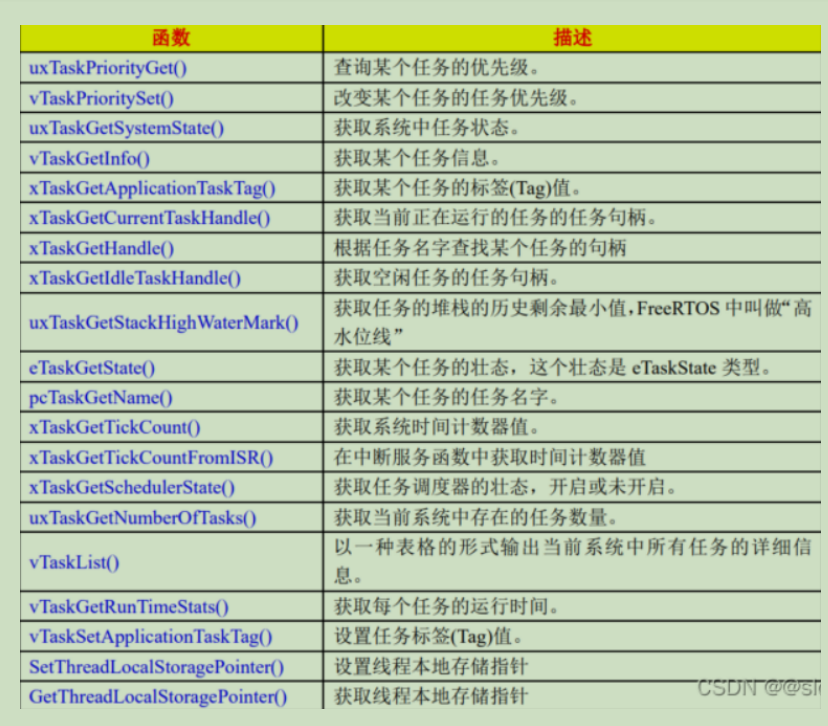
API
创建任务:
xTaskCreate()
xTaskCreateStatic()
挂起任务:
vTaskSuspend()
vTaskSuspendAll()
恢复任务:
vTaskResume() 让挂起的任务重新进入就绪状态
xTaskResumeFromISR() 专门用在中断服务程序中
xTaskResumeAll()
删除任务:
vTaskDelete()
延时任务:
vTaskDelay() 相对延时函数
vTaskDelayUntil() 绝对延时函数(适用于周期性任务)
同步互斥与通信
同步与互斥的概念
在团队活动里,同事A先写完报表,经理B才能拿去向领导汇报。经理B必须等同事A完成报表,AB之间有依赖,B必须放慢脚步,被称为同步。在团队活动中,同事A已经使用会议室了,经理B也想使用,即使经理B是领导,他也得等着,这就叫互斥。经理B跟同事A说:你用完会议室就提醒我。这就是使用”同步”来实现”互斥”。
同一时间只能有一个人使用的资源,被称为临界资源。比如任务A、B都要使用串口来打印,串口就是临界资源。如果A、B同时使用串口,那么打印出来的信息就是A、B混杂,无法分辨。所以使用串口时,应该是这样:A用完,B再用;B用完,A再用。
同步的例子
1 | static struct TaskPrintInfo g_Task1Info = {0, 0, "Task1"}; |
对于static volatile int g_calc_end = 0;
没有加volatile时,经过debug,发现程序一直会卡LcdPrintTask的while (g_calc_end == 0);处,尽管在debug时显示g_calc_end为1还是一直卡在那里。这是因为在编译器做了一些优化,第一次使用这个变量时,它会去读内存,把这个变量的值读进CPU的某个寄存器,以后在任务2的那个while循环里,它一直都是去判断那个寄存器,但是那个寄存器得到的是这个变量原始的,老的值,它并没有每次都去内存里面读这个变量,更新那个寄存器,这是不对的,因为这个变量,是在其他任务里面被修改了,你去使用这个变量时,每次都应该去读内存,怎么办呢,在变量前加一个volatile就好了,告诉编译器,不要去优化它。
“在多任务环境下,编译器通常会对变量进行优化以提高代码执行效率。当一个变量被标记为 volatile 时,它告诉编译器这个变量的值可能在程序控制范围之外发生变化(例如由中断服务程序、硬件操作或者其他并发任务修改),因此每次访问该变量时都会从内存中重新读取。编译器对变量的优化通常基于以下几种情况:
局部性原理:编译器假设在一段连续执行的代码中,如果一个变量没有被显示地修改(比如通过赋值、函数调用或指针间接访问),其值就不会改变。因此,在循环内多次读取同一变量时,编译器可能会将该变量从内存加载到寄存器中,并在整个循环期间使用寄存器中的值,以减少对内存的访问。
数据流分析:编译器会进行数据依赖性分析,如果它能确定某个变量在当前作用域内不会受外部因素影响而改变,即使这个变量是全局的,也可能对其进行优化。
跨函数优化:编译器还可能进行跨函数优化,例如当函数没有明确的副作用或者编译器能够推断出函数内部对全局变量的修改不会影响到当前上下文时,也会选择不重新加载变量。”
应当在以下情况下考虑使用
volatile关键字来修饰变量:- 变量可能被中断服务程序修改。
- 变量位于多线程环境且不同线程间共享并修改该变量。
- 变量与硬件寄存器映射相关,硬件可能会在软件不可见的情况下更改它们的值。
- 变量用于信号量、事件标志或其他同步机制。
上例LcdPrintTask任务的while函数,尽管没有后面的内容没有执行,但是它会执行while一直循环,也会占用CPU资源,实际打印出来的时间也不是计算任务实际的时间,而是实际时间的两倍,因为任务一二是每过一个TICK就交替执行的,这也是我们说的用静态变量来解决互斥问题的缺陷)。
所以使用同步的时候,我们需要考虑怎样提高处理器的性能,让那些等待的任务阻塞,不要参与CPU的调度。
PS:
debug过程
https://www.bilibili.com/video/BV1Jw411i7Fz?p=25&vd_source=a9d487fcf1a579639c6348eb5a9321db
9:25~11:05
互斥的例子
示例1

这三个任务都使用同一个函数,这个函数里面会在屏幕显示信息,屏幕就是临界资源,同一时间只能够有一个任务来访问,通过IIC访问硬件,如果不提供互斥保护措施的话 ,IIC时序会被打乱。
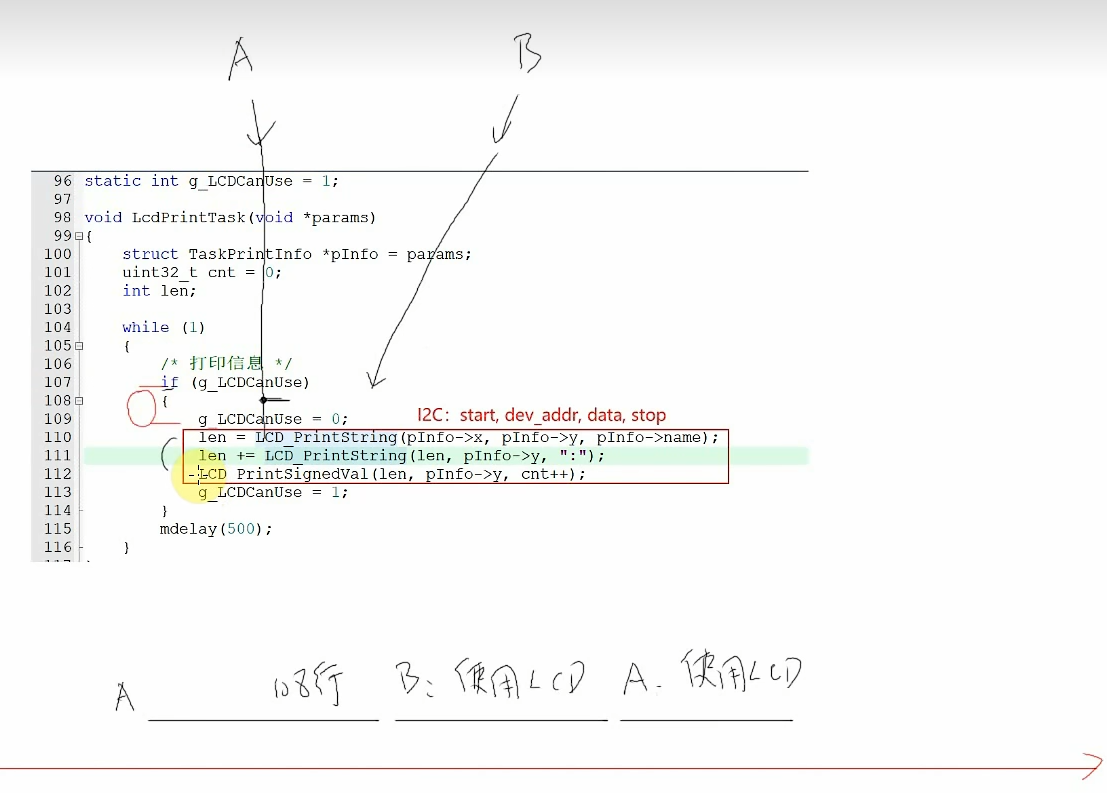
因此,使用红框内的代码操作LCD时,必须互斥访问,A没有用完,B不能够使用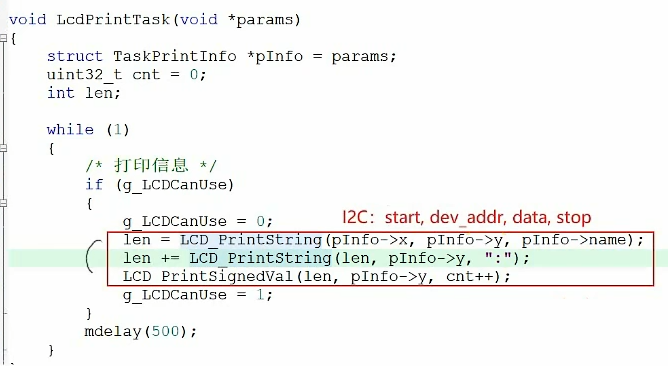
目前是用的全局变量g_LCDCanUse来互斥保护,大部分情况是可以的,但理论上它是有缺陷的:
当A运行到108行被切换了,此时g_LCDCanUse=1,B运行也可以进去,这样A和B都可以使用LCD,使IIC时序混乱。当程序运行成千上万次时,很有可能出现这样的问题。
示例2
如果改成这样,看上去貌似没什么问题,但再往细看,执行bCanUse–这一条指令时,汇编发生了三个过程。先把bCanUse存入一个寄存器,把这个寄存器的值减一,然后再赋值给bCanUse,如果A在把bCanUse存到寄存器后被切换为B,此时bCanUse还是1,减1后为0,B可以运行,再切换为A时,因为保存的有现场,所以当时的R0=1被保存下来,减1后为0,也可以运行LCD。这三个过程,它们是可以被切换的,虽然概率很小,但你不可能杜绝它。

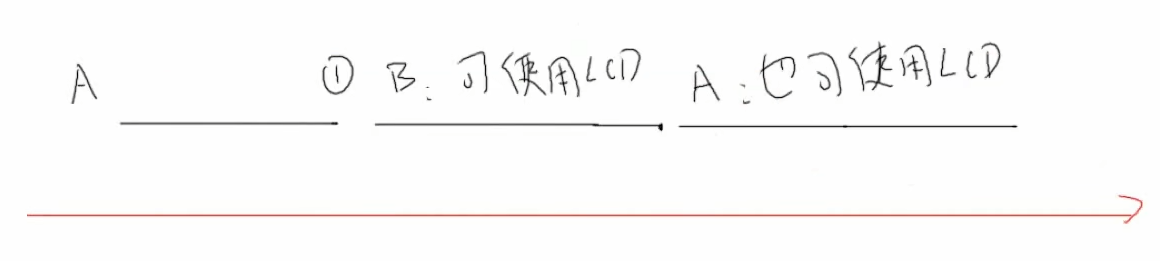
从上面的例子可以看出,如果简单的使用这种全局变量来保护临界资源,虽然大概率没问题,但当程序运行很长时间后可能出问题。
解决方法可以是关中断:
示例1的代码改进如下:在第5~7行前关闭中断。
1 | int LCD_PrintString(int x, int y, char *str) |
示例2的代码改进如下:在第5行前关闭中断。
1 | int LCD_PrintString(int x, int y, char *str) |
但这样的话 确实能行 但其实B任务也会占用CPU资源,最好的是我们应该让它阻塞,A用完了之后再把B唤醒。
通信的例子
通过一个全局变量设置状态,在AB里通信,也可能在这个全局变量还没改完就切换了,这样就通信失败了,要用互斥的方法来解决,同时要保持高效,要用阻塞。
FreeRTOS的解决方案(概述)
- 用互斥的方法保证正确性
- 效率:等待者要进入阻塞状态(阻塞和唤醒机制来提高效率)
- 多种解决方案
队列
可以认为队列是一个传送带,流水线,先进先出

事件组

信号量

互斥量

任务通知

队列
数据传输的方法

环形缓冲区
解释的很清楚: http://t.csdnimg.cn/DY7gy
环形缓冲区是嵌入式系统中十分重要的一种数据结构,比如在串口处理中,串口中断接收数据直接往环形缓冲区丢数据,而应用可以从环形缓冲区取数据进行处理,这样数据在读取和写入的时候都可以在这个缓冲区里循环进行,程序员可以根据自己需要的数据大小来决定自己使用的缓冲区大小,不用担心数组越界。
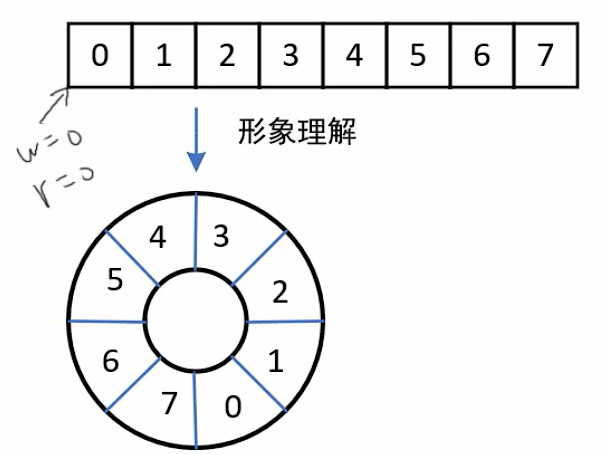
队列的基本概念:队列 (Queue):是一种先进先出(First In First Out ,简称 FIFO)的线性表,只允许在一端插入(入队),在另一端进行删除(出队)。
队列头就是指向已经存储的数据,并且这个数据是待处理的。下一个CPU处理的数据就是1;而队列尾则指向可以进行写数据的地址。
队列的最大长度queueMaxsize=数组容量arrayMaxSize-1 (由于置空位要占一位,置空位是为了让空载和满载的判断条件区别开来,否则它们都是头=尾,就不能因此来判断队列是空还是满),所以也引出了代码里的next_w。
置空位虽然是人为引入的,但这不意味这置空位的位置是随意的,实际上,只有队列满后才会将剩下的位置作为置空位,一旦置空位出现,rear和front永远不可能指向同一个索引位,因为你会惊奇的发现置空位恰号将rear和front隔开了。
示例代码
1 | //伪代码 |
1 | //应用代码 |
如果在使用场景里面只有两个任务,且不考虑阻塞-唤醒(效率),就可以使用环形缓冲区,注意不要添加一个全局变量计数值,两个任务都来修改它的话可能会出问题。
本质
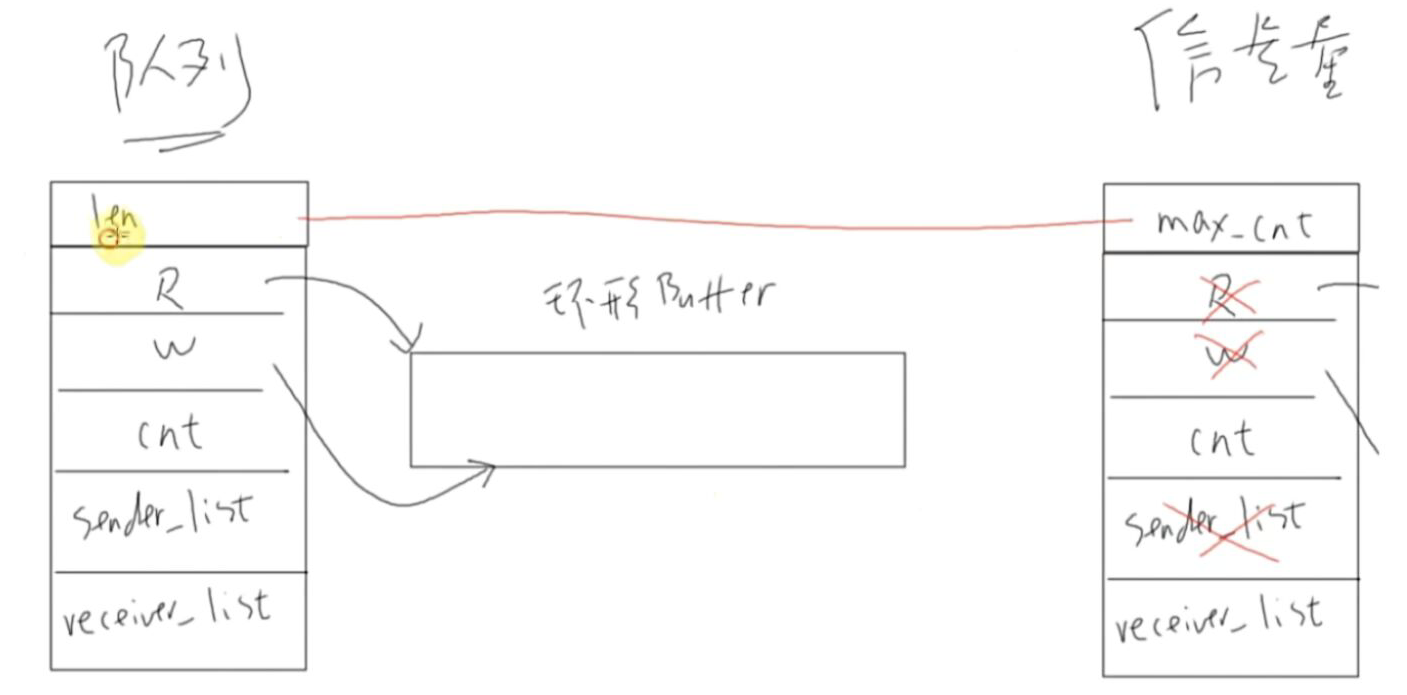
队列的本质是加了互斥措施,阻塞-唤醒机制的环形缓冲区 .
1.有环形buffer
2.两个链表: 阻塞时放到对应的链表里,Sender List, Receiver List
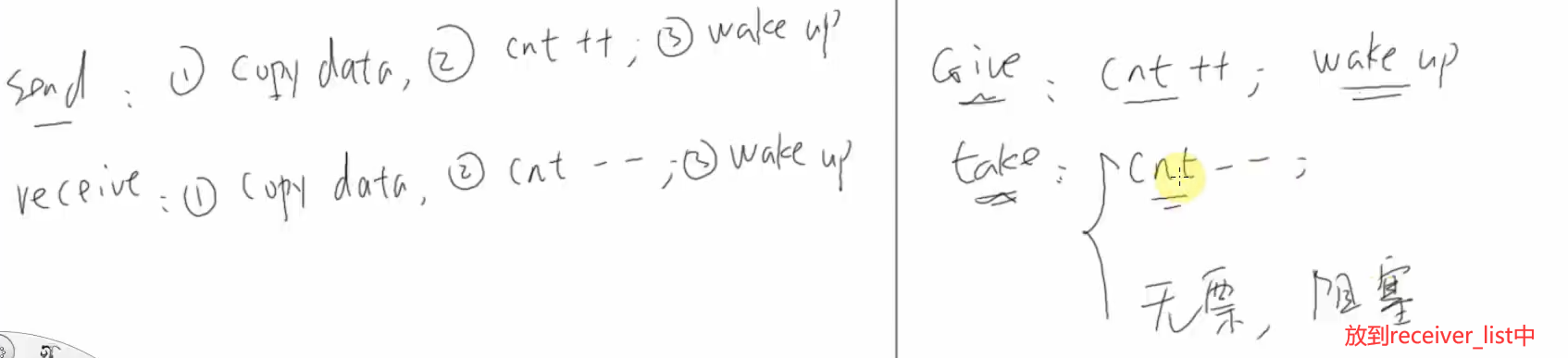
一个任务想去读队列,如果队列里没有数据读不到数据且愿意等待的话,它将会从就绪链表ReadyTaskList里移除,放到队列的接收链表Receiver List和一个Delay链表(超时时间)里,若有其他任务写队列,会把这个任务唤醒,从接收链表和Delay链表中删去,重新放到ReadyList中,若是超时的话则中断会唤醒它,放到就绪列表ReadyTaskList中,有机会运行时,它的返回值就是一个错误的,我们就知道没有数据,是超时唤醒它。
当阻塞时有两种唤醒的情况,一种是其他任务唤醒它,另一种是超时中断唤醒。
实验

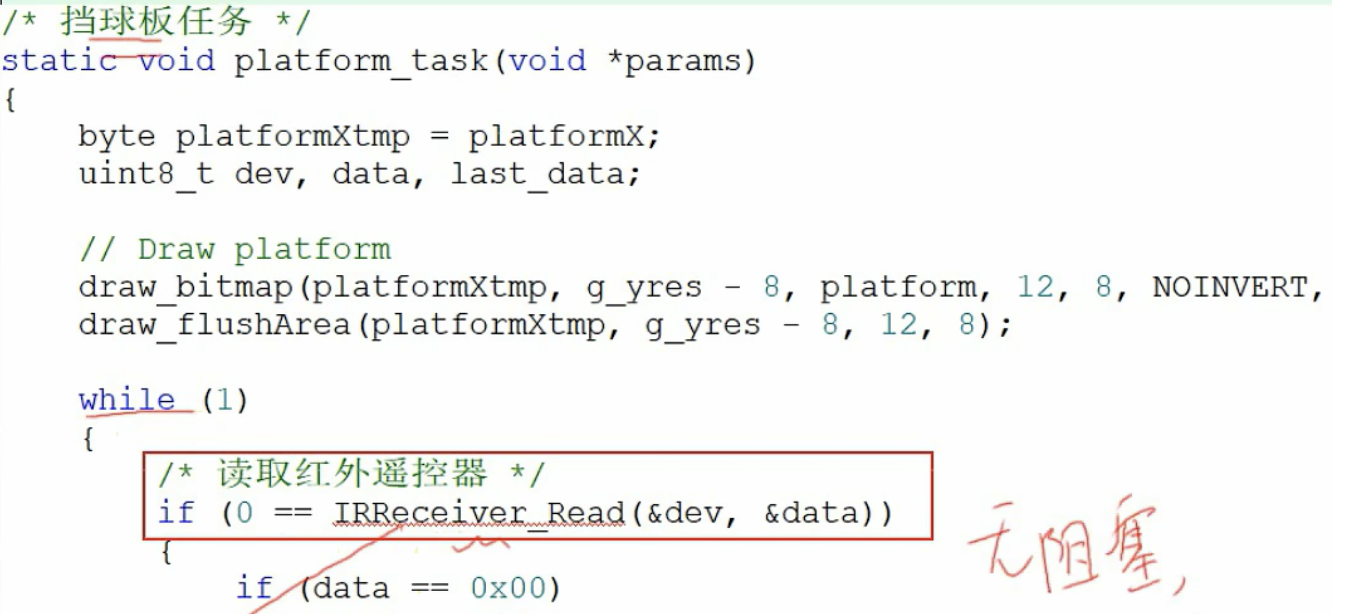
挡球板任务一直执行while循环,尝试去读,无阻塞低效率。要将其改进为读队列A,红外中断解析出数据后写队列A
1.创建一个队列A
2.在红外ISR(中断)中写队列A
3.挡球板任务中读队列A
队列集
队列集其实也是一个队列,只不过里面放的是队列的句柄。
如果对于每一个硬件都单独创建一个任务,任务需要栈空间,对于系统资源很浪费。
不管有多少个设备,只有一个任务,就不会很浪费系统资源,那么任务要怎么及时读到各个硬件的数据呢,一种是用轮询的方式(不断的运行,一直都没有阻塞,浪费CPU资源),另一种是用队列集。
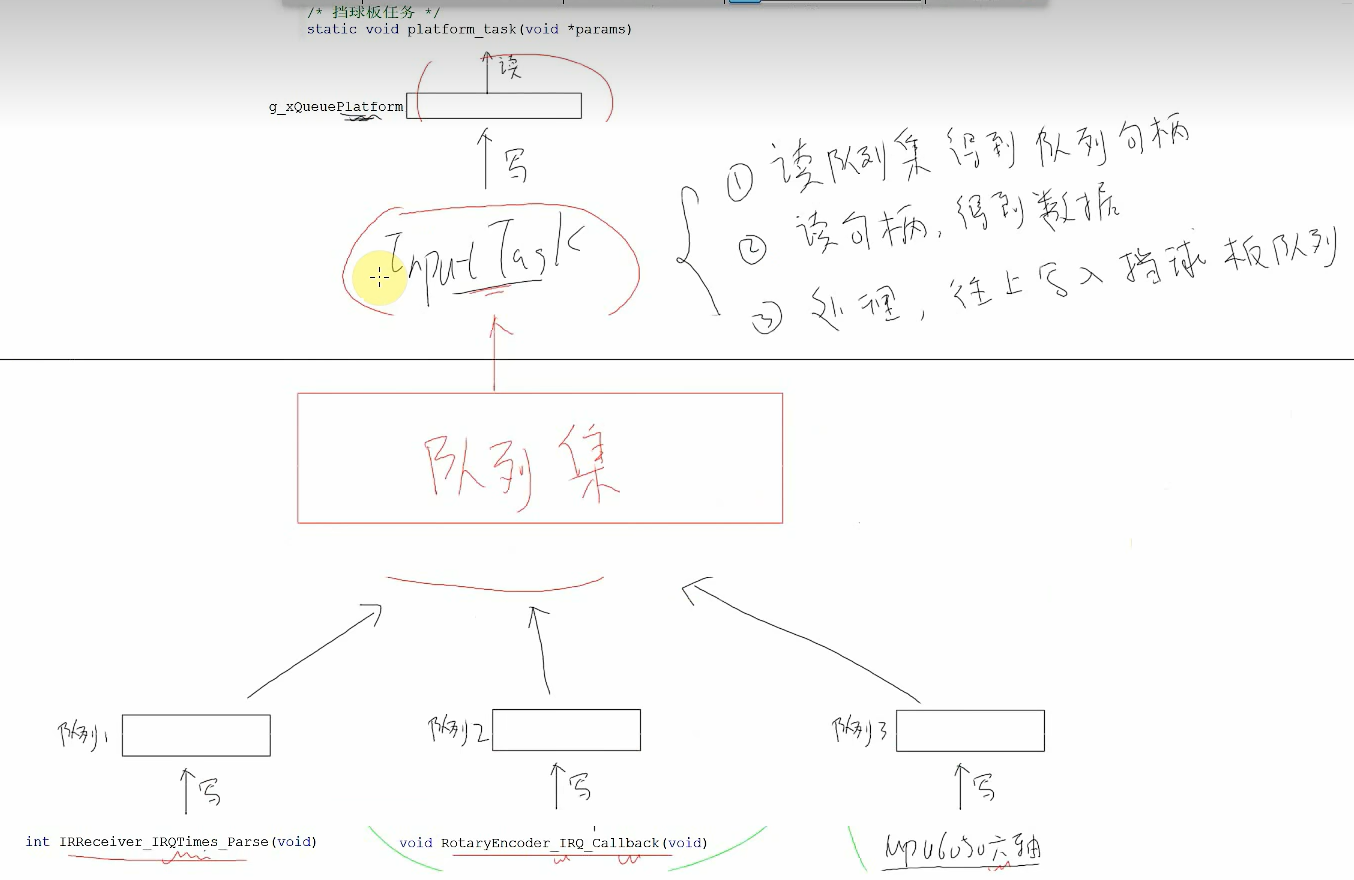
内部机制
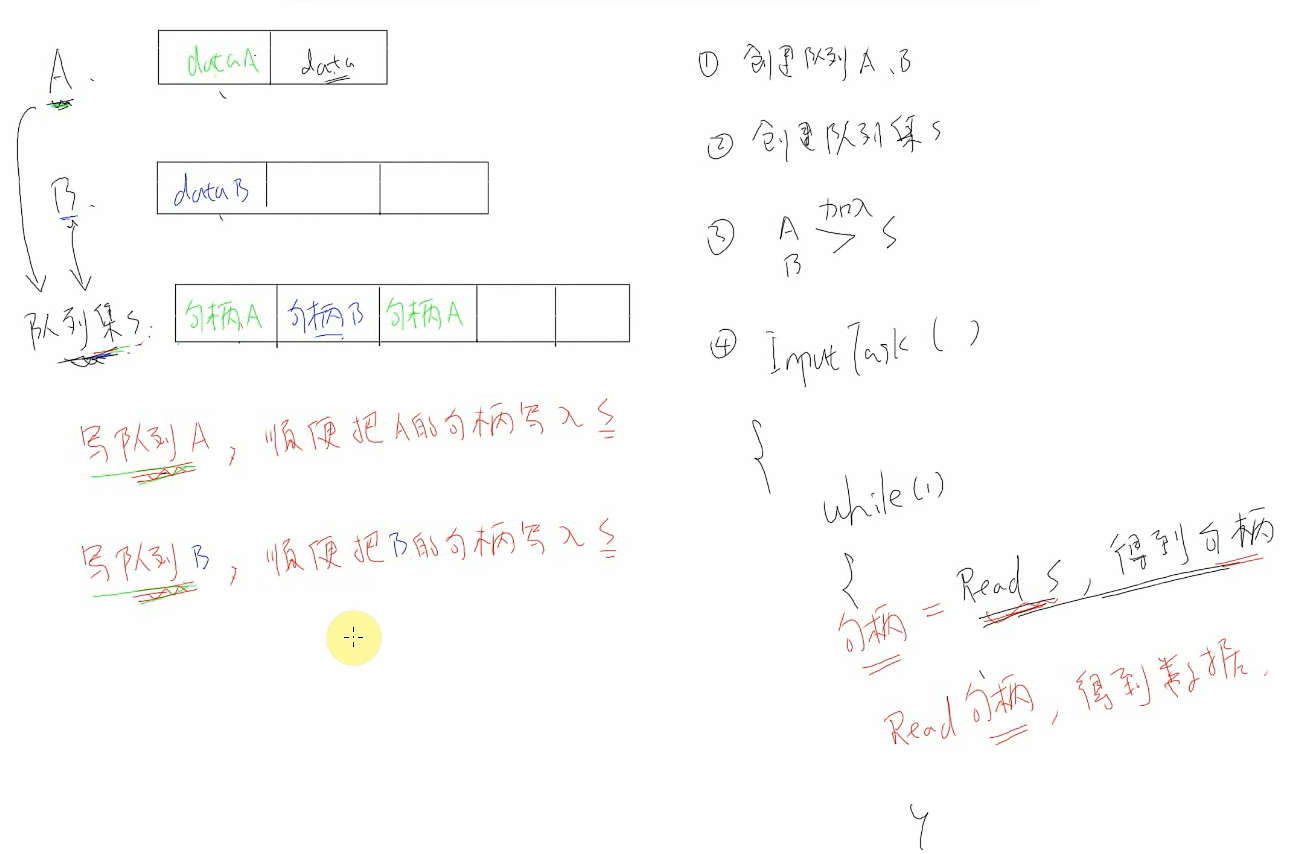
队列写了数据,必定会顺带把自己的句柄写入队列级(不用我们操作,freertos来做这些事)
队列集实验
改进程序框架
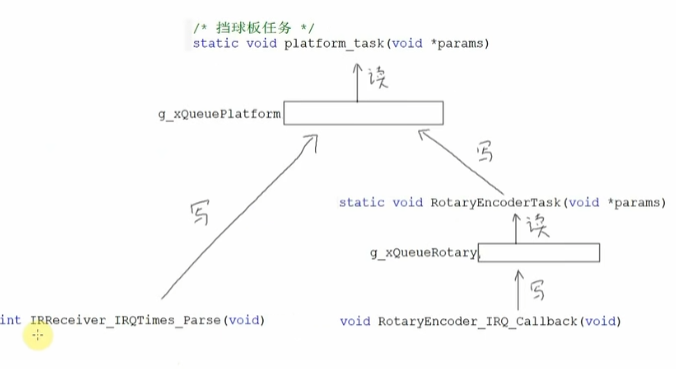
IRReceiver_IRQTimes_Parse是红外遥控器的中断函数,他解析出按键值后,会转换成游戏控制的键值,然后写入Platform队列,这就涉及到了业务上的东西,它把键值转换成游戏控制的值,这样就不纯粹了,硬件相关的程序,不应该跟业务密切相关

若对每个硬件都单独创建一个任务,对于系统的资源有极大的浪费
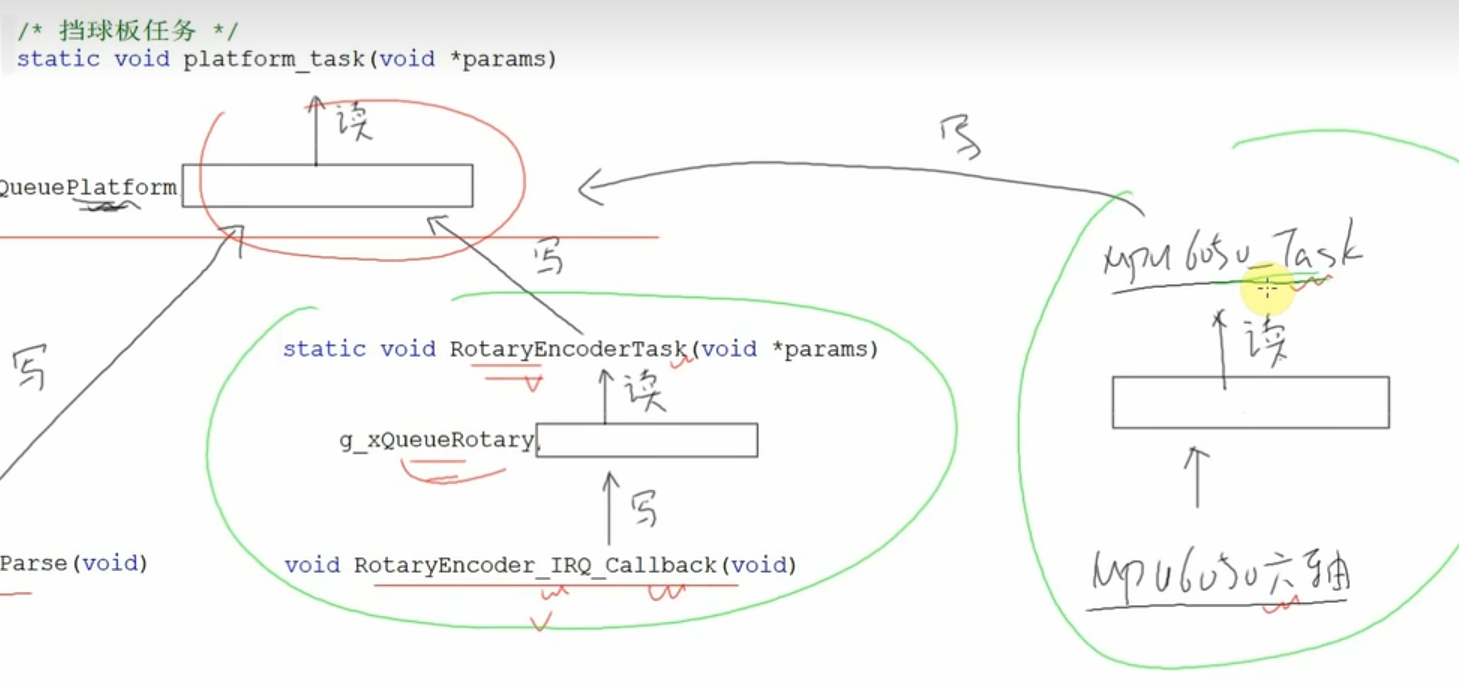
正确的做法:
硬件相关的代码与游戏没有关系
配置队列集文件
要使用队列集,得配置freeRTOS,发现CUBEMX没有相关设置

在freeRTOS.h中找到

可以直接修改,但是如果CUBEMX重新生成工程,它又被恢复,直接把它加到FreeRTOSConfig.h中
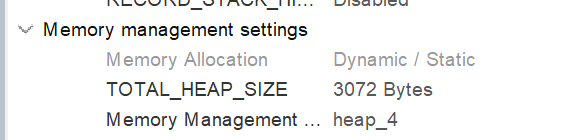
如果运行工程,发现程序正常运行,但少了一些东西,可能是内存不够,堆不够,把3072改大一点比如8000
程序15与14现象是一样的,但是框架更漂亮了。
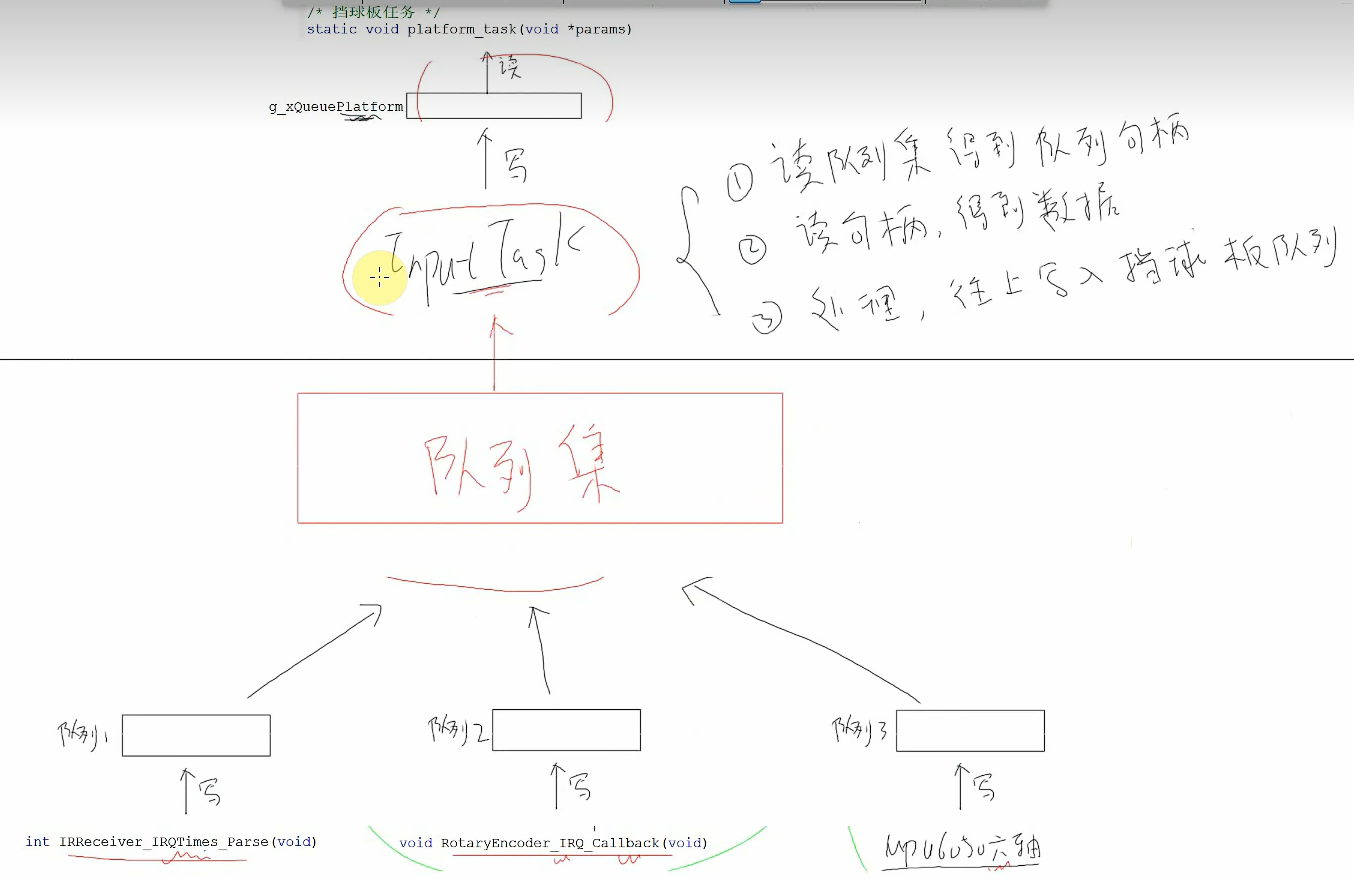
增加姿态控制
这次不是从中断获取数据,而是要创建一个任务,在while循环里面读I2C获取数据,然后写队列,然后在game任务将队列加入队列集
注意创建MPU6050任务时的顺序
刚开始是在freertos.c,在game1_task创建后马上就创建了6050的任务,如果6050的任务运行了,队列写满了,然后才把这个队列放入队列集,由于写满了,无法再向队列写数据,队列集得不到队列的句柄。(读取队列需要在队列集力先有该队列的句柄,但是这里把队列加入队列集之前队列就满了,队列写不了数据队列集也有没有句柄可读了)

所以应该要在将6050加入队列集的代码之后再创建6050的任务

(实验)分发数据给多个任务
赛车游戏
引入了一个有意思的东西,比如想使用同一个输入数据来控制多个任务,可以在驱动程序里面,去写多个队列,去写哪些队列,其决定权可以交给应用程序,应用程序调用一个所谓的注册函数把它的句柄告诉驱动程序,驱动程序会把它记录下来。
如果只是一个队列,三个任务从这个队列读数据,则一个任务把数据读走了之后,另外两个任务就读不到数据了,所以要给每个任务创建一个队列,在红外中断解析函数得到数据后直接使用DispatchKey函数分配,把数据给各个队列都写一份,各个队列依据数据里的control_key判断是否是自己的。
可以这么写,但是写的比较丑陋,以后增加一个队列的话,又得来修改这些代码,且代码跟car密切相关,那这套代码就只能用在car上
1 | static void DispatchKey(struct ir_data *pidata) |
改造一下:
1 | //driver_ir_receiver.c |
1 | //game2.c |
首先car_game()创建三个任务,对应三辆汽车,传入的&g_cars[0],&g_cars[1],&g_cars[2],其中存放着它们各自的参数。这三个任务使用同一个CarTask函数,只是参数不同。
在CarTask函数中,会创建一个队列,属于当前任务,然后把这个队列注册(加到g_xQueues[10]中)。
然后再中断解析函数中调用dispatch函数,使用for循环,把解析出的数据给每一个队列都写一份数据,对应任务识别到自己相应control_key后才会继续响应。
信号量
本质
信号量本质上也是一个队列,但是它不涉及数据的传输,只涉及到里面数据个数的统计
例子
把信号量看成门票
取票为take,放票为give
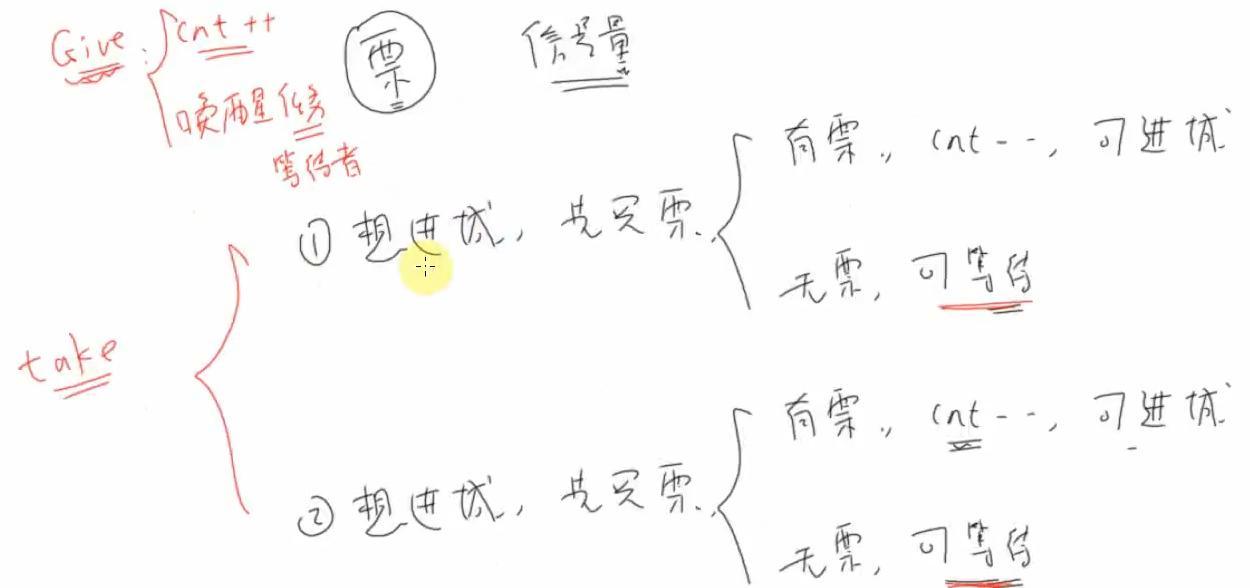
信号量与队列对比
对于阻塞的任务,高优先级排在前面,当信号量增加时会先唤醒高优先级的任务,同等优先级任务按先来后到的顺序执行。
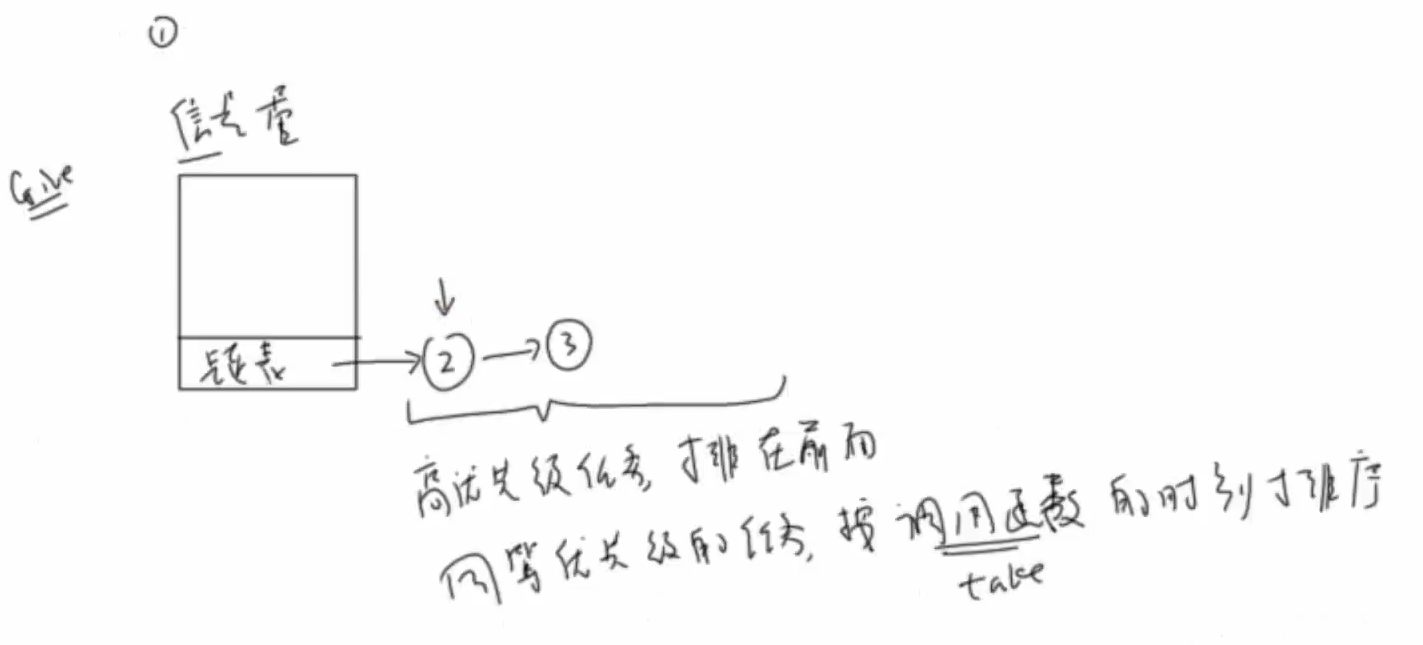
例子
1 | static SemaphoreHandle_t g_xSemTicks; |
优先级反转
低优先级的任务先运行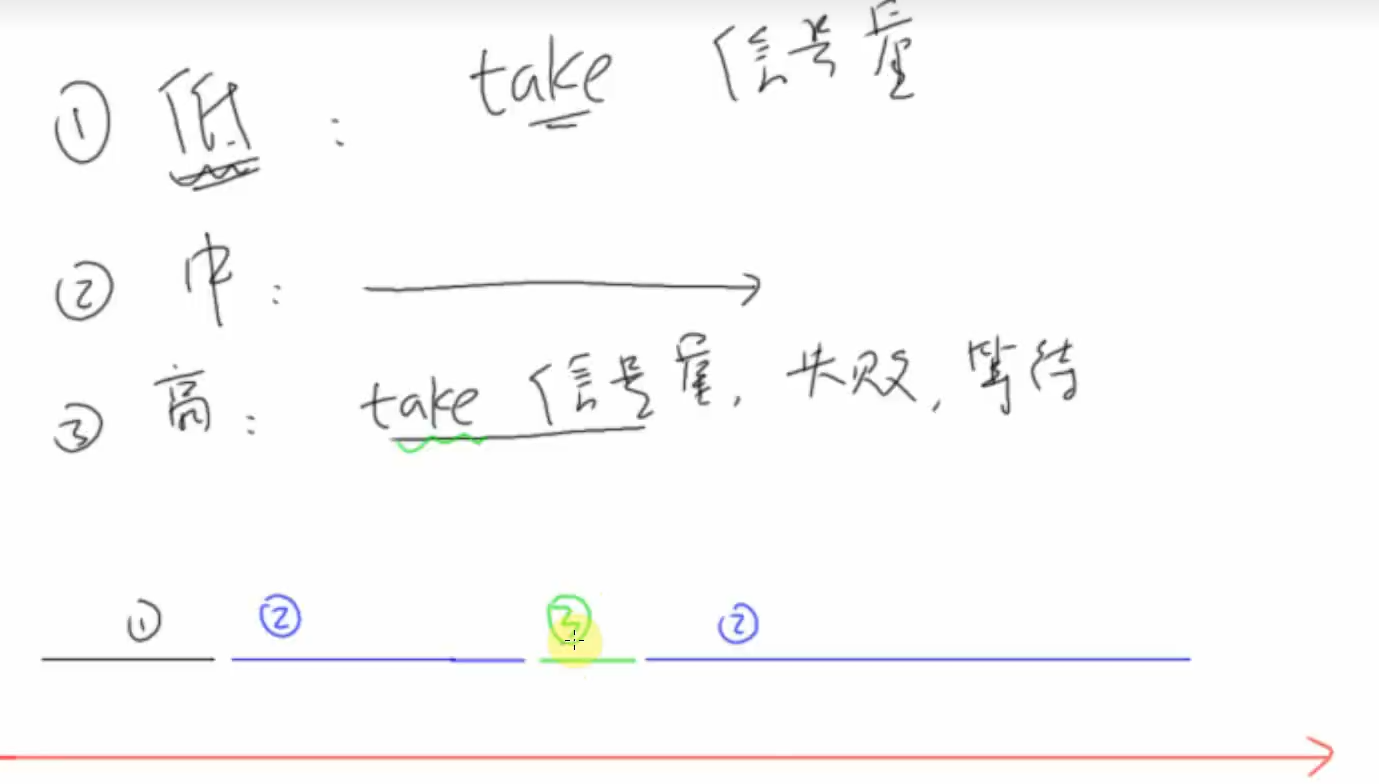
上面这个例子,低优先级的任务先创建,并取走了信号量,然后中优先级的任务创建,执行一些东西,阻塞第一个任务且它不去获得信号量,然后高优先级的任务创建,阻塞中优先级任务并调用take函数,由于信号量被低优先级的任务取走了,所以它会阻塞,中优先级的任务继续执行,汽车到终点后自杀结束任务,然后低优先级的任务继续执行,汽车执行到终点后释放信号量,高优先级的任务才开始运行,从而实现了优先级反转。

API
使用信号量时,先创建、然后去添加资源、获得资源。使用句柄来表示一个信号量。
创建
使用信号量之前,要先创建,得到一个句柄;使用信号量时,要使用句柄来表明使用哪个信号量。 对于二进制信号量、计数型信号量,它们的创建函数不一样:
| 二进制信号量 | 计数型信号量 | |
|---|---|---|
| 动态创建 | xSemaphoreCreateBinary 计数值初始值为0 | xSemaphoreCreateCounting |
| vSemaphoreCreateBinary(过时了) 计数值初始值为1 | ||
| 静态创建 | xSemaphoreCreateBinaryStatic | xSemaphoreCreateCountingStatic |
创建二进制信号量的函数原型如下:
1 | /* 创建一个二进制信号量,返回它的句柄。 |
创建计数型信号量的函数原型如下:
1 | /* 创建一个计数型信号量,返回它的句柄。 |
删除
对于动态创建的信号量,不再需要它们时,可以删除它们以回收内存。
vSemaphoreDelete可以用来删除二进制信号量、计数型信号量,函数原型如下:
1 | /* |
give/take
二进制信号量、计数型信号量的give、take操作函数是一样的。这些函数也分为2个版本:给任务使用,给ISR使用。列表如下:
| 在任务中使用 | 在ISR中使用 | |
|---|---|---|
| give | xSemaphoreGive | xSemaphoreGiveFromISR |
| take | xSemaphoreTake | xSemaphoreTakeFromISR |
xSemaphoreGive的函数原型如下:
1 | BaseType_t xSemaphoreGive( SemaphoreHandle_t xSemaphore ); |
xSemaphoreGive函数的参数与返回值列表如下:
| 参数 | 说明 |
|---|---|
| xSemaphore | 信号量句柄,释放哪个信号量 |
| 返回值 | pdTRUE表示成功, 如果二进制信号量的计数值已经是1,再次调用此函数则返回失败; 如果计数型信号量的计数值已经是最大值,再次调用此函数则返回失败 |
pxHigherPriorityTaskWoken的函数原型如下:
1 | BaseType_t xSemaphoreGiveFromISR( |
xSemaphoreGiveFromISR函数的参数与返回值列表如下:
| 参数 | 说明 |
|---|---|
| xSemaphore | 信号量句柄,释放哪个信号量 |
| pxHigherPriorityTaskWoken | 如果释放信号量导致更高优先级的任务变为了就绪态, 则*pxHigherPriorityTaskWoken = pdTRUE |
| 返回值 | pdTRUE表示成功, 如果二进制信号量的计数值已经是1,再次调用此函数则返回失败; 如果计数型信号量的计数值已经是最大值,再次调用此函数则返回失败 |
xSemaphoreTake的函数原型如下:
1 | BaseType_t xSemaphoreTake( |
xSemaphoreTake函数的参数与返回值列表如下:
| 参数 | 说明 |
|---|---|
| xSemaphore | 信号量句柄,获取哪个信号量 |
| xTicksToWait | 如果无法马上获得信号量,阻塞一会: 0:不阻塞,马上返回 portMAX_DELAY: 一直阻塞直到成功 其他值: 阻塞的Tick个数,可以使用*pdMS_TO_TICKS()*来指定阻塞时间为若干ms |
| 返回值 | pdTRUE表示成功 |
xSemaphoreTakeFromISR的函数原型如下:
1 | BaseType_t xSemaphoreTakeFromISR( |
xSemaphoreTakeFromISR函数的参数与返回值列表如下:
| 参数 | 说明 |
|---|---|
| xSemaphore | 信号量句柄,获取哪个信号量 |
| pxHigherPriorityTaskWoken | 如果获取信号量导致更高优先级的任务变为了就绪态, 则*pxHigherPriorityTaskWoken = pdTRUE |
| 返回值 | pdTRUE表示成功 |
互斥量
是信号量的一种变种
解决优先级反转
例

学生在用超算(指纹验证),主任带人来参观实验室,对学生说太吵了,先别用,然后校长也来了要用超算,但是因为学生已经指纹验证了,所以它得等着,用互斥量的话就是校长临时提拔(学生继承校长优先级)学生到他的级别,然后学生继续用超算,用完了后就识相的恢复自己的级别(优先级),然后校长来用超算,校长用完了之后主任带人参观
保护临界资源
eg: I2C互斥访问,同时只能有一个使用I2C,否则会使数据传输失败。所以要加上互斥锁
单纯的使用全局变量来保护有风险,比如当任务二执行bInUsed=1后,任务三被创建,任务二被阻塞,而bInUsed还没被清零,所以任务三一直卡在while。
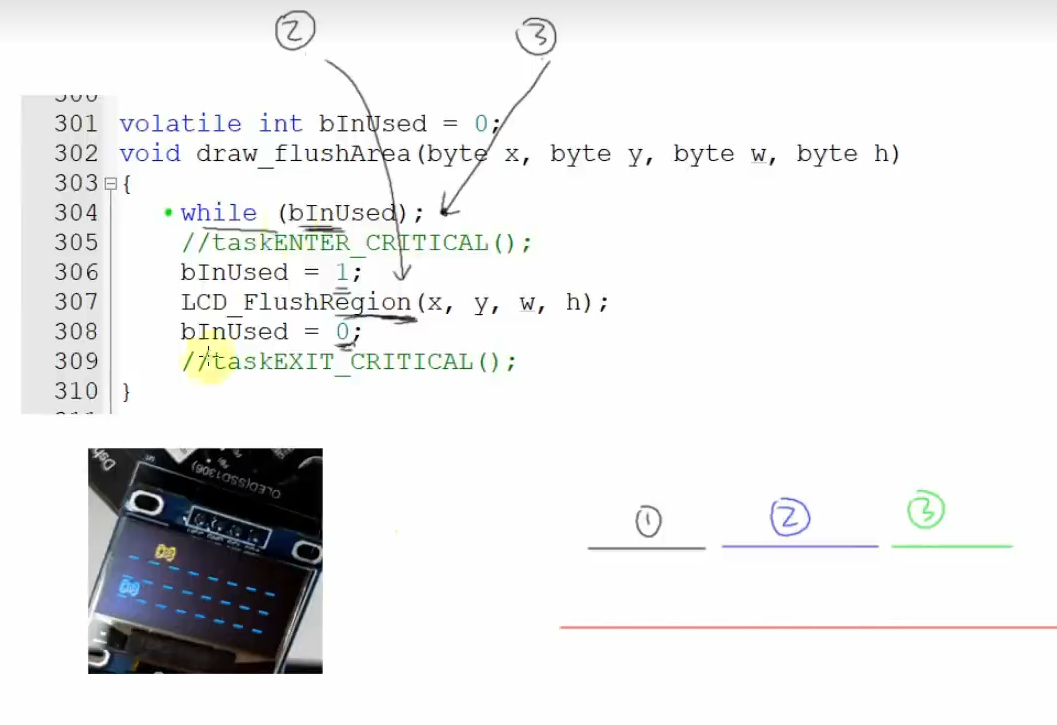
任务A访问这些全局变量、函数代码时,独占它,就是上个锁。这些全局变量、函数代码必须被独占地使用,它们被称为临界资源。
互斥量也被称为互斥锁,使用过程如下:
- 互斥量初始值为1
- 任务A想访问临界资源,先获得并占有互斥量,然后开始访问
- 任务B也想访问临界资源,也要先获得互斥量:被别人占有了,于是阻塞
- 任务A使用完毕,释放互斥量;任务B被唤醒、得到并占有互斥量,然后开始访问临界资源
- 任务B使用完毕,释放互斥量
1 | //freertos.c |
API
创建
互斥量是一种特殊的二进制信号量。
使用互斥量时,先创建、然后去获得、释放它。使用句柄来表示一个互斥量。
创建互斥量的函数有2种:动态分配内存,静态分配内存,函数原型如下:
1 | /* 创建一个互斥量,返回它的句柄。 |
要想使用互斥量,需要在配置文件FreeRTOSConfig.h中定义:
1 |
其他函数
要注意的是,互斥量不能在ISR中使用。
各类操作函数,比如删除、give/take,跟一般是信号量是一样的。
1 | /* |
事件组
本质
事件组可以简单地认为就是一个整数:
- 每一位表示一个事件
- 每一位事件的含义由程序员决定,比如:Bit0表示用来串口是否就绪,Bit1表示按键是否被按下
- 这些位,值为1表示事件发生了,值为0表示事件没发生
- 一个或多个任务、ISR都可以去写这些位;一个或多个任务、ISR都可以去读这些位
- 可以等待某一位、某些位中的任意一个,也可以等待多位
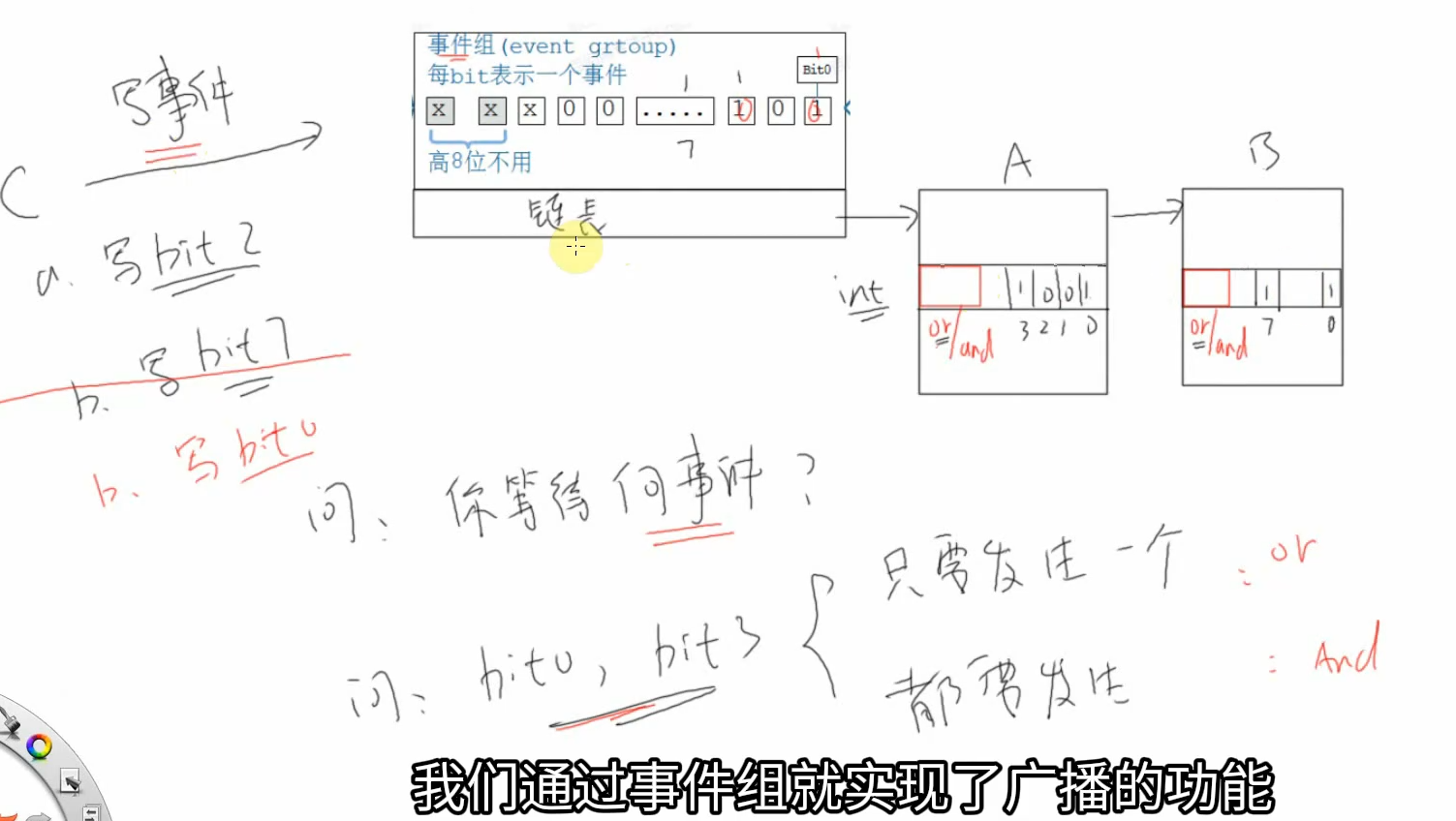
事件组用一个整数来表示,其中的高8位留给内核使用,只能用其他的位来表示事件。那么这个整数是多少位的?
- 如果configUSE_16_BIT_TICKS是1,那么这个整数就是16位的,低8位用来表示事件
- 如果configUSE_16_BIT_TICKS是0,那么这个整数就是32位的,低24位用来表示事件
- configUSE_16_BIT_TICKS是用来表示Tick Count的,怎么会影响事件组?这只是基于效率来考虑
- 如果configUSE_16_BIT_TICKS是1,就表示该处理器使用16位更高效,所以事件组也使用16位
- 如果configUSE_16_BIT_TICKS是0,就表示该处理器使用32位更高效,所以事件组也使用32位
例:car1或car2到站后,car3启动
car1,car2到站后,分别设置事件组bit0和bit1, car3一开始等待事件bit1或bit1, car1,car2任意一个先到站后,就会触发car3行驶
1 | xEventGroupSetBits(g_xEventCar,(1<<1)); |
1 | game2.c |
事件组的操作
事件组和队列、信号量等不太一样,主要集中在2个地方:
唤醒谁?
- 队列、信号量:事件发生时,只会唤醒一个任务
- 事件组:事件发生时,会唤醒所有符号条件的任务,简单地说它有”广播”的作用
是否清除事件?
- 队列、信号量:是消耗型的资源,队列的数据被读走就没了;信号量被获取后就减少了
- 事件组:被唤醒的任务有两个选择,可以让事件保留不动,也可以清除事件
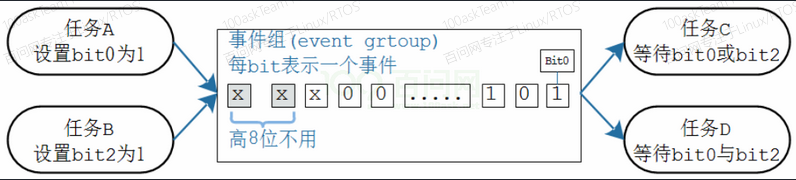
以上图为列,事件组的常规操作如下:
- 先创建事件组
- 任务C、D等待事件:
- 等待什么事件?可以等待某一位、某些位中的任意一个,也可以等待多位。简单地说就是”或”、”与”的关系。
- 得到事件时,要不要清除?可选择清除、不清除。
- 任务A、B产生事件:设置事件组里的某一位、某些位
实验
改进姿态控制

之前驱动MPU6050任务是先创建一个任务,在里面一直读I2C,然后写队列,这样的话如果姿态没变,还是一直在读I2C,浪费资源,
可以采用在中断中写事件组来唤醒任务,任务在开始一直等待事件,被唤醒后才去读I2C,写队列
1 | driver_mpu6050.c |
中断配置
注意使用中断的话,首先可以从原理图看到MPU6050的中断引脚是PB5
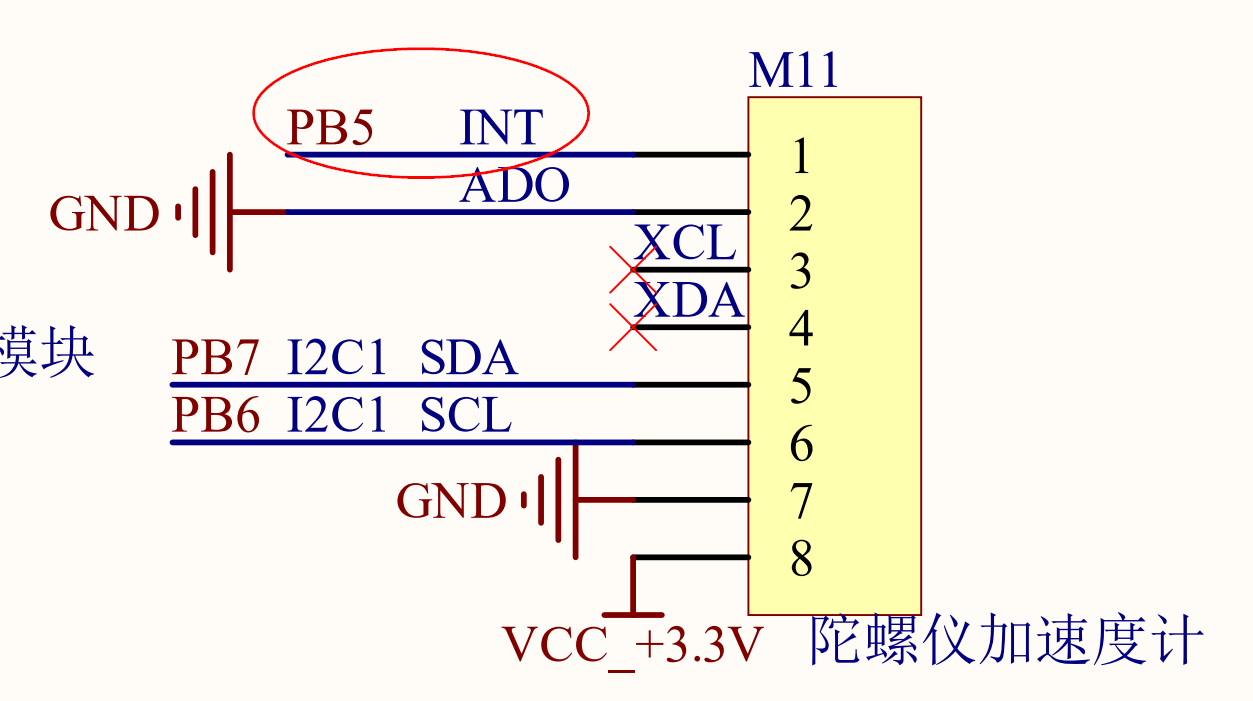
在cubemx中,将PB5引脚配置成外部中断
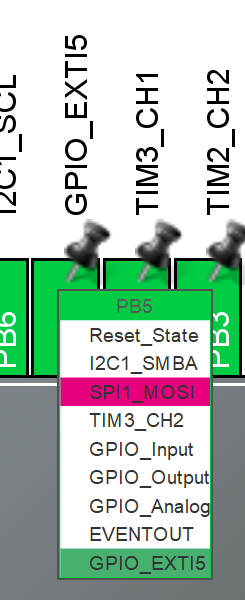

触发中断时产生高电平信号,则配置PB5为上升沿触发

然后配置NVIC使能

接着我们要去找到PB5的中断处理函数
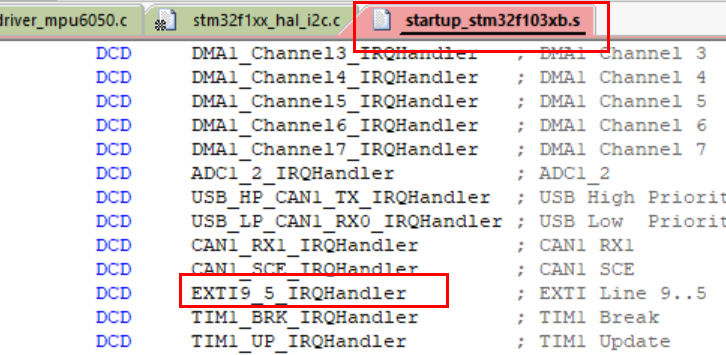
1 | void HAL_GPIO_EXTI_Callback(uint16_t GPIO_Pin) |
其次也要配置MPU6050中断引脚,并开启中断
需要我们去写MPU6050寄存器

1 | int MPU6050_Init(void) |
API
创建
使用事件组之前,要先创建,得到一个句柄;使用事件组时,要使用句柄来表明使用哪个事件组。
有两种创建方法:动态分配内存、静态分配内存。函数原型如下:
1 | /* 创建一个事件组,返回它的句柄。 |
删除
对于动态创建的事件组,不再需要它们时,可以删除它们以回收内存。
vEventGroupDelete可以用来删除事件组,函数原型如下:
1 | /* |
设置事件
可以设置事件组的某个位、某些位,使用的函数有2个:
- 在任务中使用xEventGroupSetBits()
- 在ISR中使用xEventGroupSetBitsFromISR()
有一个或多个任务在等待事件,如果这些事件符合这些任务的期望,那么任务还会被唤醒。
函数原型如下:
1 | /* 设置事件组中的位 |
值得注意的是,ISR中的函数,比如队列函数xQueueSendToBackFromISR、信号量函数xSemaphoreGiveFromISR,它们会唤醒某个任务,最多只会唤醒1个任务。
但是设置事件组时,有可能导致多个任务被唤醒,这会带来很大的不确定性。所以xEventGroupSetBitsFromISR函数不是直接去设置事件组,而是给一个FreeRTOS后台任务(daemon task)发送队列数据,由这个任务来设置事件组。
如果后台任务的优先级比当前被中断的任务优先级高,xEventGroupSetBitsFromISR会设置*pxHigherPriorityTaskWoken为pdTRUE。
如果daemon task成功地把队列数据发送给了后台任务,那么xEventGroupSetBitsFromISR的返回值就是pdPASS。
等待事件
使用xEventGroupWaitBits来等待事件,可以等待某一位、某些位中的任意一个,也可以等待多位;等到期望的事件后,还可以清除某些位。
函数原型如下:
1 | EventBits_t xEventGroupWaitBits( EventGroupHandle_t xEventGroup, |
先引入一个概念:unblock condition。一个任务在等待事件发生时,它处于阻塞状态;当期望的时间发生时,这个状态就叫”unblock condition”,非阻塞条件,或称为”非阻塞条件成立”;当”非阻塞条件成立”后,该任务就可以变为就绪态。
函数参数说明列表如下:
| 参数 | 说明 |
|---|---|
| xEventGroup | 等待哪个事件组? |
| uxBitsToWaitFor | 等待哪些位?哪些位要被测试? |
| xWaitForAllBits | 怎么测试?是”AND”还是”OR”? pdTRUE: 等待的位,全部为1; pdFALSE: 等待的位,某一个为1即可 |
| xClearOnExit | 函数提出前是否要清除事件? pdTRUE: 清除uxBitsToWaitFor指定的位 pdFALSE: 不清除 |
| xTicksToWait | 如果期待的事件未发生,阻塞多久。 可以设置为0:判断后即刻返回; 可设置为portMAX_DELAY:一定等到成功才返回; 可以设置为期望的Tick Count,一般用*pdMS_TO_TICKS()*把ms转换为Tick Count |
| 返回值 | 返回的是事件值, 如果期待的事件发生了,返回的是”非阻塞条件成立”时的事件值; 如果是超时退出,返回的是超时时刻的事件值。 |
举例如下:
| 事件组的值 | uxBitsToWaitFor | xWaitForAllBits | 说明 |
|---|---|---|---|
| 0100 | 0101 | pdTRUE | 任务期望bit0,bit2都为1, 当前值只有bit2满足,任务进入阻塞态; 当事件组中bit0,bit2都为1时退出阻塞态 |
| 0100 | 0110 | pdFALSE | 任务期望bit0,bit2某一个为1, 当前值满足,所以任务成功退出 |
| 0100 | 0110 | pdTRUE | 任务期望bit1,bit2都为1, 当前值不满足,任务进入阻塞态; 当事件组中bit1,bit2都为1时退出阻塞态 |
你可以使用*xEventGroupWaitBits()等待期望的事件,它发生之后再使用xEventGroupClearBits()*来清除。但是这两个函数之间,有可能被其他任务或中断抢占,它们可能会修改事件组。
可以使用设置xClearOnExit为pdTRUE,使得对事件组的测试、清零都在*xEventGroupWaitBits()*函数内部完成,这是一个原子操作。
同步点
有一个事情需要多个任务协同,比如:
- 任务A:炒菜
- 任务B:买酒
- 任务C:摆台
- A、B、C做好自己的事后,还要等别人做完;大家一起做完,才可开饭
使用 xEventGroupSync() 函数可以同步多个任务:
- 可以设置某位、某些位,表示自己做了什么事
- 可以等待某位、某些位,表示要等等其他任务
- 期望的时间发生后, xEventGroupSync() 才会成功返回。
- xEventGroupSync成功返回后,会清除事件
xEventGroupSync 函数原型如下:
1 | EventBits_t xEventGroupSync( EventGroupHandle_t xEventGroup, |
参数列表如下:
| 参数 | 说明 |
|---|---|
| xEventGroup | 哪个事件组? |
| uxBitsToSet | 要设置哪些事件?我完成了哪些事件? 比如0x05(二进制为0101)会导致事件组的bit0,bit2被设置为1 |
| uxBitsToWaitFor | 等待那个位、哪些位? 比如0x15(二级制10101),表示要等待bit0,bit2,bit4都为1 |
| xTicksToWait | 如果期待的事件未发生,阻塞多久。 可以设置为0:判断后即刻返回; 可设置为portMAX_DELAY:一定等到成功才返回; 可以设置为期望的Tick Count,一般用*pdMS_TO_TICKS()*把ms转换为Tick Count |
| 返回值 | 返回的是事件值, 如果期待的事件发生了,返回的是”非阻塞条件成立”时的事件值; 如果是超时退出,返回的是超时时刻的事件值。 |
参数列表如下:
| 参数 | 说明 |
|---|---|
| xEventGroup | 哪个事件组? |
| uxBitsToSet | 要设置哪些事件?我完成了哪些事件? 比如0x05(二进制为0101)会导致事件组的bit0,bit2被设置为1 |
| uxBitsToWaitFor | 等待那个位、哪些位? 比如0x15(二级制10101),表示要等待bit0,bit2,bit4都为1 |
| xTicksToWait | 如果期待的事件未发生,阻塞多久。 可以设置为0:判断后即刻返回; 可设置为portMAX_DELAY:一定等到成功才返回; 可以设置为期望的Tick Count,一般用*pdMS_TO_TICKS()*把ms转换为Tick Count |
| 返回值 | 返回的是事件值, 如果期待的事件发生了,返回的是”非阻塞条件成立”时的事件值; 如果是超时退出,返回的是超时时刻的事件值。 |
任务通知
本质
我们使用队列、信号量、事件组等等方法时,并不知道对方是谁。使用任务通知时,可以明确指定:通知哪个任务。
使用队列、信号量、事件组时,我们都要事先创建对应的结构体,双方通过中间的结构体通信:

使用任务通知时,任务结构体TCB中就包含了内部对象,可以直接接收别人发过来的”通知”:

通知状态和通知值
每个任务都有一个结构体:TCB(Task Control Block),里面有2个成员:
- 一个是uint8_t类型,用来表示通知状态
- 一个是uint32_t类型,用来表示通知值
1 | typedef struct tskTaskControlBlock |
通知状态有3种取值:
- taskNOT_WAITING_NOTIFICATION:任务没有在等待通知
- taskWAITING_NOTIFICATION:任务在等待通知
- taskNOTIFICATION_RECEIVED:任务接收到了通知,也被称为pending(有数据了,待处理)
1 | # |
通知值可以有很多种类型:
- 计数值
- 位(类似事件组)
- 任意数值
场景1:
B最开始是taskNOT_WAITING_NOTIFICATION ,然后因为一些其它东西阻塞了(不是因为要等待任务通知),状态仍是taskNOT_WAITING_NOTIFICATION ,这时A发来通知,也无法唤醒B,但是B确实是收到了通知,所以状态改变为taskNOTIFICATION_RECEIVED,然后过一段时间后任务不再阻塞,这时候状态仍是taskNOTIFICATION_RECEIVED,然后这时如果任务B想看看收到的东西,它会调用函数,这时由于之前已经收到了东西,所以状态直接变为taskNOT_WAITING_NOTIFICATION。
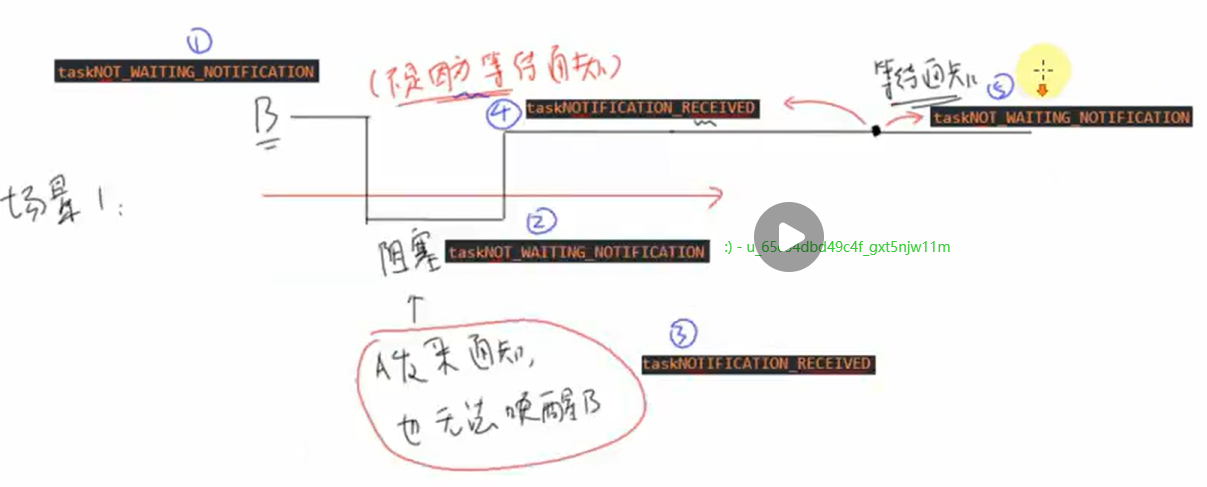
场景2:开始时B的状态为taskNOT_WAITING_NOTIFICATION,然后它想等待通知,阻塞,状态变为 taskWAITING_NOTIFICATION,这时A发来通知,状态切换为taskNOTIFICATION_RECEIVED,唤醒B后状态又变为taskNOT_WAITING_NOTIFICATION
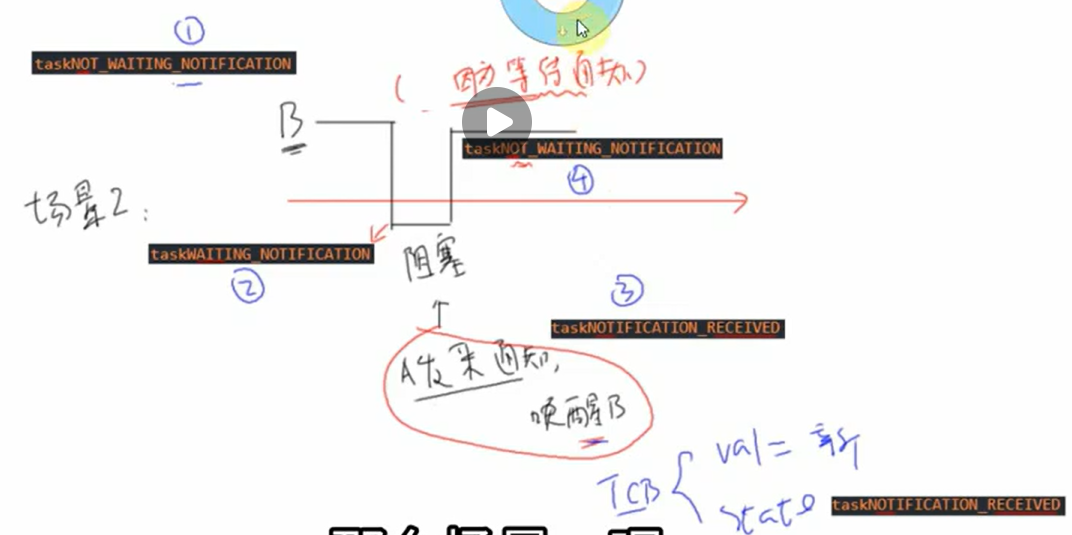
实验
让第一辆车到达终点后发出任务通知给第二辆第三辆
1 | game2.c |
API
任务通知的使用
使用任务通知,可以实现轻量级的队列(长度为1)、邮箱(覆盖的队列)、计数型信号量、二进制信号量、事件组。
两类函数
任务通知有2套函数,简化版、专业版,列表如下:
- 简化版函数的使用比较简单,它实际上也是使用专业版函数实现的
- 专业版函数支持很多参数,可以实现很多功能
| 简化版 | 专业版 | |
|---|---|---|
| 发出通知 | xTaskNotifyGive vTaskNotifyGiveFromISR | xTaskNotify xTaskNotifyFromISR |
| 取出通知 | ulTaskNotifyTake | xTaskNotifyWait |
xTaskNotifyGive/ulTaskNotifyTake
在任务中使用xTaskNotifyGive函数,在ISR中使用vTaskNotifyGiveFromISR函数,都是直接给其他任务发送通知:
- 使得通知值加一 cnt++
- 并使得通知状态变为”pending”,也就是taskNOTIFICATION_RECEIVED,表示有数据了、待处理
可以使用ulTaskNotifyTake函数来取出通知值:
- 如果通知值等于0,则阻塞(可以指定超时时间)
- 当通知值大于0时,任务从阻塞态进入就绪态
- 在ulTaskNotifyTake返回之前,还可以做些清理工作:把通知值减一,或者把通知值清零
使用ulTaskNotifyTake函数可以实现轻量级的、高效的二进制信号量、计数型信号量。
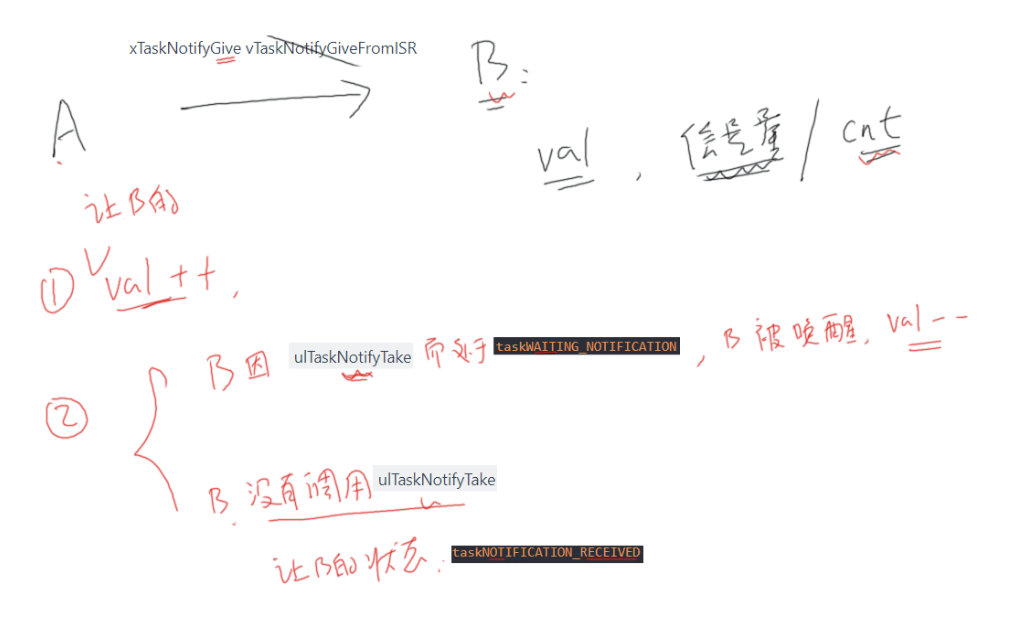
这几个函数的原型如下:
1 | BaseType_t xTaskNotifyGive( TaskHandle_t xTaskToNotify ); |
xTaskNotifyGive函数的参数说明如下:
| 参数 | 说明 |
|---|---|
| xTaskToNotify | 任务句柄(创建任务时得到),给哪个任务发通知 |
| 返回值 | 必定返回pdPASS |
vTaskNotifyGiveFromISR函数的参数说明如下:
| 参数 | 说明 |
|---|---|
| xTaskHandle | 任务句柄(创建任务时得到),给哪个任务发通知 |
| pxHigherPriorityTaskWoken | 被通知的任务,可能正处于阻塞状态。 此函数发出通知后,会把它从阻塞状态切换为就绪态。 如果被唤醒的任务的优先级,高于当前任务的优先级, 则”*pxHigherPriorityTaskWoken”被设置为pdTRUE, 这表示在中断返回之前要进行任务切换。 |
ulTaskNotifyTake函数的参数说明如下:
| 参数 | 说明 |
|---|---|
| xClearCountOnExit | 函数返回前是否清零: pdTRUE:把通知值清零 pdFALSE:如果通知值大于0,则把通知值减一 |
| xTicksToWait | 任务进入阻塞态的超时时间,它在等待通知值大于0。 0:不等待,即刻返回; portMAX_DELAY:一直等待,直到通知值大于0; 其他值:Tick Count,可以用*pdMS_TO_TICKS()*把ms转换为Tick Count |
| 返回值 | 函数返回之前,在清零或减一之前的通知值。 如果xTicksToWait非0,则返回值有2种情况: 1. 大于0:在超时前,通知值被增加了 2. 等于0:一直没有其他任务增加通知值,最后超时返回0 |
xTaskNotify/xTaskNotifyWait
xTaskNotify 函数功能更强大,可以使用不同参数实现各类功能,比如:
- 让接收任务的通知值加一:这时 xTaskNotify() 等同于 xTaskNotifyGive()
- 设置接收任务的通知值的某一位、某些位,这就是一个轻量级的、更高效的事件组
- 把一个新值写入接收任务的通知值:上一次的通知值被读走后,写入才成功。这就是轻量级的、长度为1的队列
- 用一个新值覆盖接收任务的通知值:无论上一次的通知值是否被读走,覆盖都成功。类似 xQueueOverwrite() 函数,这就是轻量级的邮箱。
xTaskNotify() 比 xTaskNotifyGive() 更灵活、强大,使用上也就更复杂。xTaskNotifyFromISR() 是它对应的ISR版本。
这两个函数用来发出任务通知,使用哪个函数来取出任务通知呢?
使用 xTaskNotifyWait() 函数!它比 ulTaskNotifyTake() 更复杂:
- 可以让任务等待(可以加上超时时间),等到任务状态为”pending”(也就是有数据)
- 还可以在函数进入、退出时,清除通知值的指定位
这几个函数的原型如下:
1 | BaseType_t xTaskNotify( TaskHandle_t xTaskToNotify, uint32_t ulValue, eNotifyAction eAction ); |
xTaskNotify函数的参数说明如下:
| 参数 | 说明 |
|---|---|
| xTaskToNotify | 任务句柄(创建任务时得到),给哪个任务发通知 |
| ulValue | 怎么使用ulValue,由eAction参数决定 |
| eAction | 见下表 |
| 返回值 | pdPASS:成功,大部分调用都会成功 pdFAIL:只有一种情况会失败,当eAction为eSetValueWithoutOverwrite, 并且通知状态为”pending”(表示有新数据未读),这时就会失败。 |
eNotifyAction参数说明:
| eNotifyAction取值 | 说明 |
|---|---|
| eNoAction | 仅仅是更新通知状态为”pending”,未使用ulValue。 这个选项相当于轻量级的、更高效的二进制信号量。 |
| eSetBits | 通知值 = 原来的通知值 | ulValue,按位或。 相当于轻量级的、更高效的事件组。 |
| eIncrement | 通知值 = 原来的通知值 + 1,未使用ulValue。 相当于轻量级的、更高效的二进制信号量、计数型信号量。 相当于**xTaskNotifyGive()**函数。 |
| eSetValueWithoutOverwrite | 不覆盖。 如果通知状态为”pending”(表示有数据未读), 则此次调用xTaskNotify不做任何事,返回pdFAIL。 如果通知状态不是”pending”(表示没有新数据), 则:通知值 = ulValue。 |
| eSetValueWithOverwrite | 覆盖。 无论如何,不管通知状态是否为”pendng”, 通知值 = ulValue。 |
xTaskNotifyFromISR函数跟xTaskNotify很类似,就多了最后一个参数pxHigherPriorityTaskWoken。在很多ISR函数中,这个参数的作用都是类似的,使用场景如下:
- 被通知的任务,可能正处于阻塞状态
- xTaskNotifyFromISR函数发出通知后,会把接收任务从阻塞状态切换为就绪态
- 如果被唤醒的任务的优先级,高于当前任务的优先级,则”*pxHigherPriorityTaskWoken”被设置为pdTRUE,这表示在中断返回之前要进行任务切换。
xTaskNotifyWait函数列表如下:
| 参数 | 说明 |
|---|---|
| ulBitsToClearOnEntry | 在xTaskNotifyWait入口处,要清除通知值的哪些位? 通知状态不是”pending”的情况下,才会清除。 它的本意是:我想等待某些事件发生,所以先把”旧数据”的某些位清零。 能清零的话:通知值 = 通知值 & ~(ulBitsToClearOnEntry)。 比如传入0x01,表示清除通知值的bit0; 传入0xffffffff即ULONG_MAX,表示清除所有位,即把值设置为0 |
| ulBitsToClearOnExit | 在xTaskNotifyWait出口处,如果不是因为超时推出,而是因为得到了数据而退出时: 通知值 = 通知值 & ~(ulBitsToClearOnExit)。 在清除某些位之前,通知值先被赋给”*pulNotificationValue”。 比如入0x03,表示清除通知值的bit0、bit1; 传入0xffffffff即ULONG_MAX,表示清除所有位,即把值设置为0 |
| pulNotificationValue | 用来取出通知值。 在函数退出时,使用ulBitsToClearOnExit清除之前,把通知值赋给”*pulNotificationValue”。 如果不需要取出通知值,可以设为NULL。 |
| xTicksToWait | 任务进入阻塞态的超时时间,它在等待通知状态变为”pending”。 0:不等待,即刻返回; portMAX_DELAY:一直等待,直到通知状态变为”pending”; 其他值:Tick Count,可以用*pdMS_TO_TICKS()*把ms转换为Tick Count |
| 返回值 | 1. pdPASS:成功 这表示xTaskNotifyWait成功获得了通知: 可能是调用函数之前,通知状态就是”pending”; 也可能是在阻塞期间,通知状态变为了”pending”。 2. pdFAIL:没有得到通知。 |

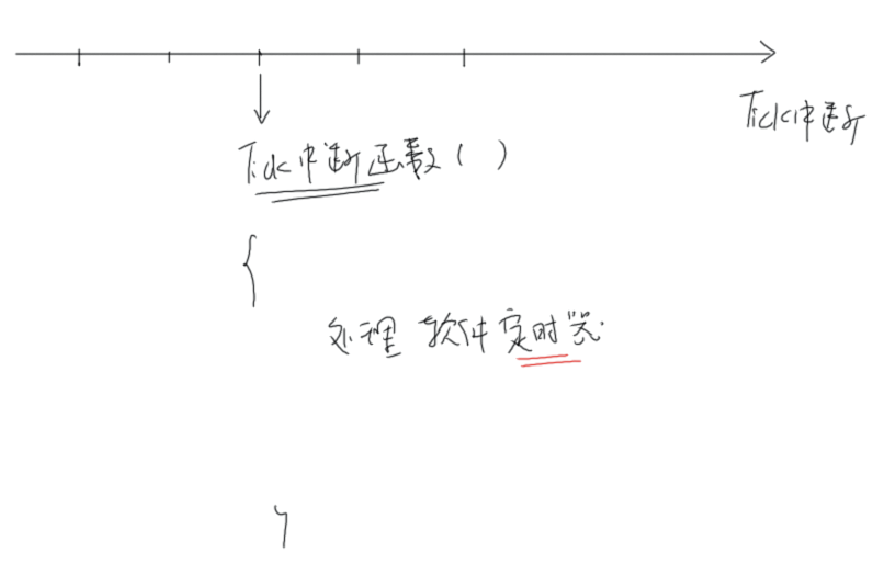
软件定时器
在硬件中断函数中被调用
软件定时器本质是一个结构体

使用定时器跟使用手机闹钟是类似的:
- 指定时间:启动定时器和运行回调函数,两者的间隔被称为定时器的周期(period)。
- 指定类型,定时器有两种类型:
- 一次性(One-shot timers): 这类定时器启动后,它的回调函数只会被调用一次; 可以手工再次启动它,但是不会自动启动它。
- 自动加载定时器(Auto-reload timers ): 这类定时器启动后,时间到之后它会自动启动它; 这使得回调函数被周期性地调用。
- 指定要做什么事,就是指定回调函数
实际的闹钟分为:有效、无效两类。软件定时器也是类似的,它由两种状态:
- 运行(Running、Active):运行态的定时器,当指定时间到达之后,它的回调函数会被调用
- 冬眠(Dormant):冬眠态的定时器还可以通过句柄来访问它,但是它不再运行,它的回调函数不会被调用
使用定时器跟使用手机闹钟是类似的:
- 指定时间:启动定时器和运行回调函数,两者的间隔被称为定时器的周期(period)。
- 指定类型,定时器有两种类型:
- 一次性(One-shot timers): 这类定时器启动后,它的回调函数只会被调用一次; 可以手工再次启动它,但是不会自动启动它。
- 自动加载定时器(Auto-reload timers ): 这类定时器启动后,时间到之后它会自动启动它; 这使得回调函数被周期性地调用。
- 指定要做什么事,就是指定回调函数
实际的闹钟分为:有效、无效两类。软件定时器也是类似的,它由两种状态:
- 运行(Running、Active):运行态的定时器,当指定时间到达之后,它的回调函数会被调用
- 冬眠(Dormant):冬眠态的定时器还可以通过句柄来访问它,但是它不再运行,它的回调函数不会被调用
cubemx配置软件定时器任务优先级

1 | beep.c |
软件定时器部分,课程内容不是很多,后面用到了再继续补充吧。
中断管理
中断要尽快处理完 ,所以两套代码的实现方式不一样,也不能一样
在RTOS中,需要应对各类事件。这些事件很多时候是通过硬件中断产生,怎么处理中断呢?
假设当前系统正在运行Task1时,用户按下了按键,触发了按键中断。这个中断的处理流程如下:
- CPU跳到固定地址去执行代码,这个固定地址通常被称为中断向量,这个跳转时硬件实现的
- 执行代码做什么?
- 保存现场:Task1被打断,需要先保存Task1的运行环境,比如各类寄存器的值
- 分辨中断、调用处理函数(这个函数就被称为ISR,interrupt service routine)
- 恢复现场:继续运行Task1,或者运行其他优先级更高的任务
你要注意到,ISR是在内核中被调用的,ISR执行过程中,用户的任务无法执行。ISR要尽量快,否则:
- 其他低优先级的中断无法被处理:实时性无法保证
- 用户任务无法被执行:系统显得很卡顿
如果这个硬件中断的处理,就是非常耗费时间呢?对于这类中断的处理就要分为2部分:
- ISR:尽快做些清理、记录工作,然后触发某个任务
- 任务:更复杂的事情放在任务中处理
- 所以:需要ISR和任务之间进行通信
要在FreeRTOS中熟练使用中断,有几个原则要先说明:
- FreeRTOS把任务认为是硬件无关的,任务的优先级由程序员决定,任务何时运行由调度器决定
- ISR虽然也是使用软件实现的,但是它被认为是硬件特性的一部分,因为它跟硬件密切相关
- 何时执行?由硬件决定
- 哪个ISR被执行?由硬件决定
- ISR的优先级高于任务:即使是优先级最低的中断,它的优先级也高于任务。任务只有在没有中断的情况下,才能执行。
切换任务
xHigherPriorityTaskWoken参数
xHigherPriorityTaskWoken的含义是:是否有更高优先级的任务被唤醒了。如果为pdTRUE,则意味着后面要进行任务切换。
还是以写队列为例。
任务A调用 xQueueSendToBack() 写队列,有几种情况发生:
- 队列满了,任务A阻塞等待,另一个任务B运行
- 队列没满,任务A成功写入队列,但是它导致另一个任务B被唤醒,任务B的优先级更高:任务B先运行
- 队列没满,任务A成功写入队列,即刻返回
可以看到,在任务中调用API函数可能导致任务阻塞、任务切换,这叫做”context switch”,上下文切换。这个函数可能很长时间才返回,在函数的内部实现了任务切换。
xQueueSendToBackFromISR() 函数也可能导致任务切换,但是不会在函数内部进行切换,而是返回一个参数:表示是否需要切换,函数原型与用法如下:
1 | /* |
pxHigherPriorityTaskWoken参数,就是用来保存函数的结果:是否需要切换
- *pxHigherPriorityTaskWoken等于pdTRUE:函数的操作导致更高优先级的任务就绪了,ISR应该进行任务切换
- *pxHigherPriorityTaskWoken等于pdFALSE:没有进行任务切换的必要
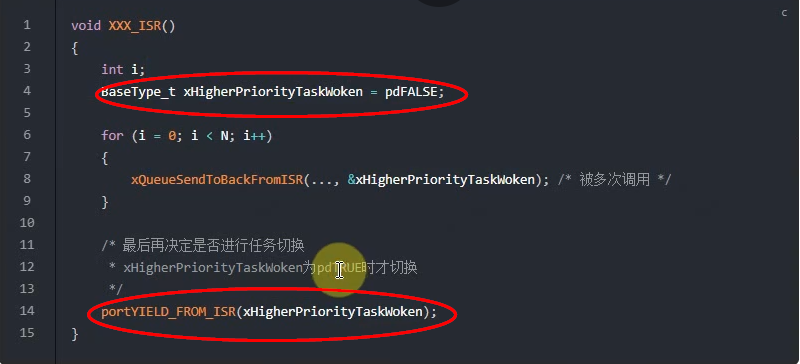
为什么不在”FromISR”函数内部进行任务切换,而只是标记一下而已呢?为了效率!示例代码如下:
1 | void XXX_ISR() |
ISR中有可能多次调用”FromISR”函数,如果在”FromISR”内部进行任务切换,会浪费时间。解决方法是:
- 在”FromISR”中标记是否需要切换
- 在ISR返回之前再进行任务切换
- 示例代码如下
1 | void XXX_ISR() |
上述的例子很常见,比如UART中断:在UART的ISR中读取多个字符,发现收到回车符时才进行任务切换。
在ISR中调用API时不进行任务切换,而只是在”xHigherPriorityTaskWoken”中标记一下,除了效率,还有多种好处:
- 效率高:避免不必要的任务切换
- 让ISR更可控:中断随机产生,在API中进行任务切换的话,可能导致问题更复杂
- 可移植性
- 在Tick中断中,调用 vApplicationTickHook() :它运行与ISR,只能使用”FromISR”的函数
使用”FromISR”函数时,如果不想使用xHigherPriorityTaskWoken参数,可以设置为NULL。
改进实时性
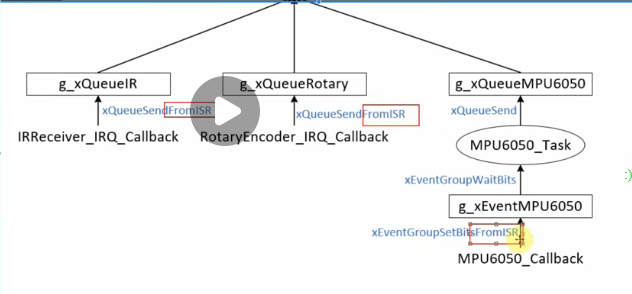
之前的代码有点小问题,在中断函数结束之前,应该发起调度,这样如果唤醒了更高优先级的任务,能在退出中断后立即执行,否则的话中断结束后还是之前那个低优先级的任务执行直到下一个tick中断再次发起调度。
虽然影响的时间对人来说可能感觉不到有什么影响,但是对于计算机的实时性还是有影响的
1 | static void DispatchKey(struct ir_data *pidata) |
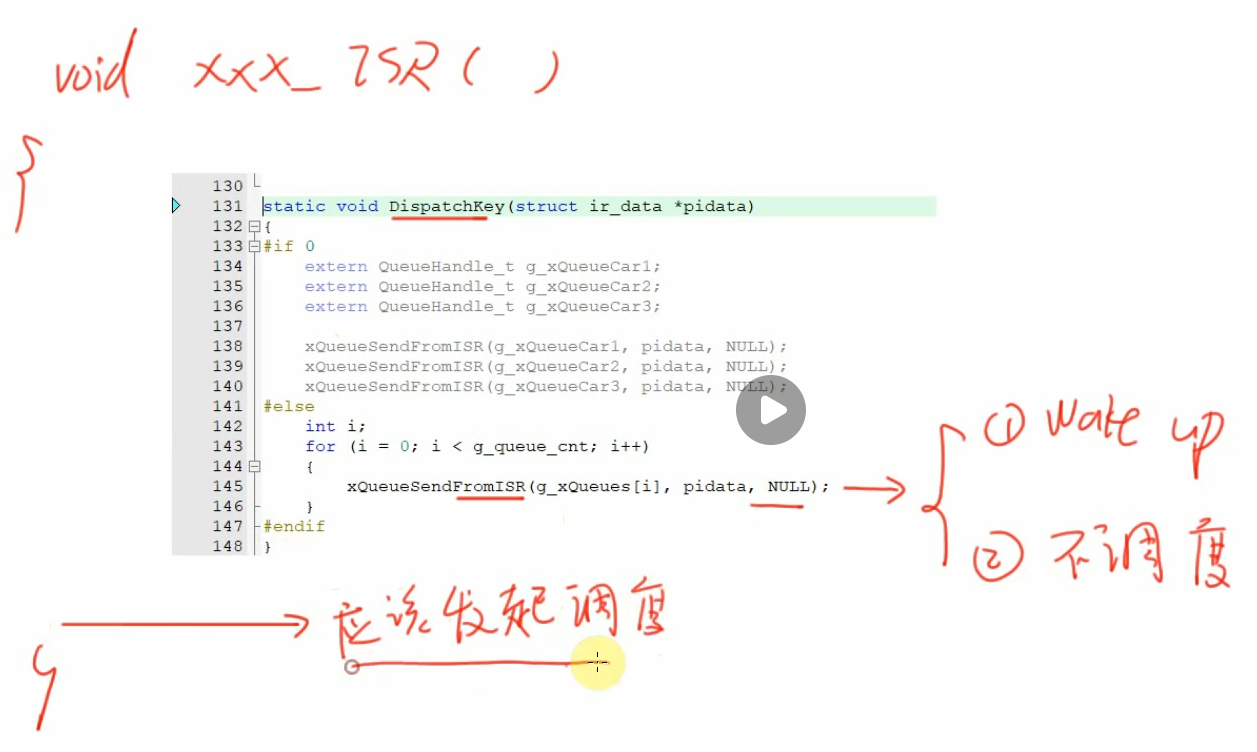
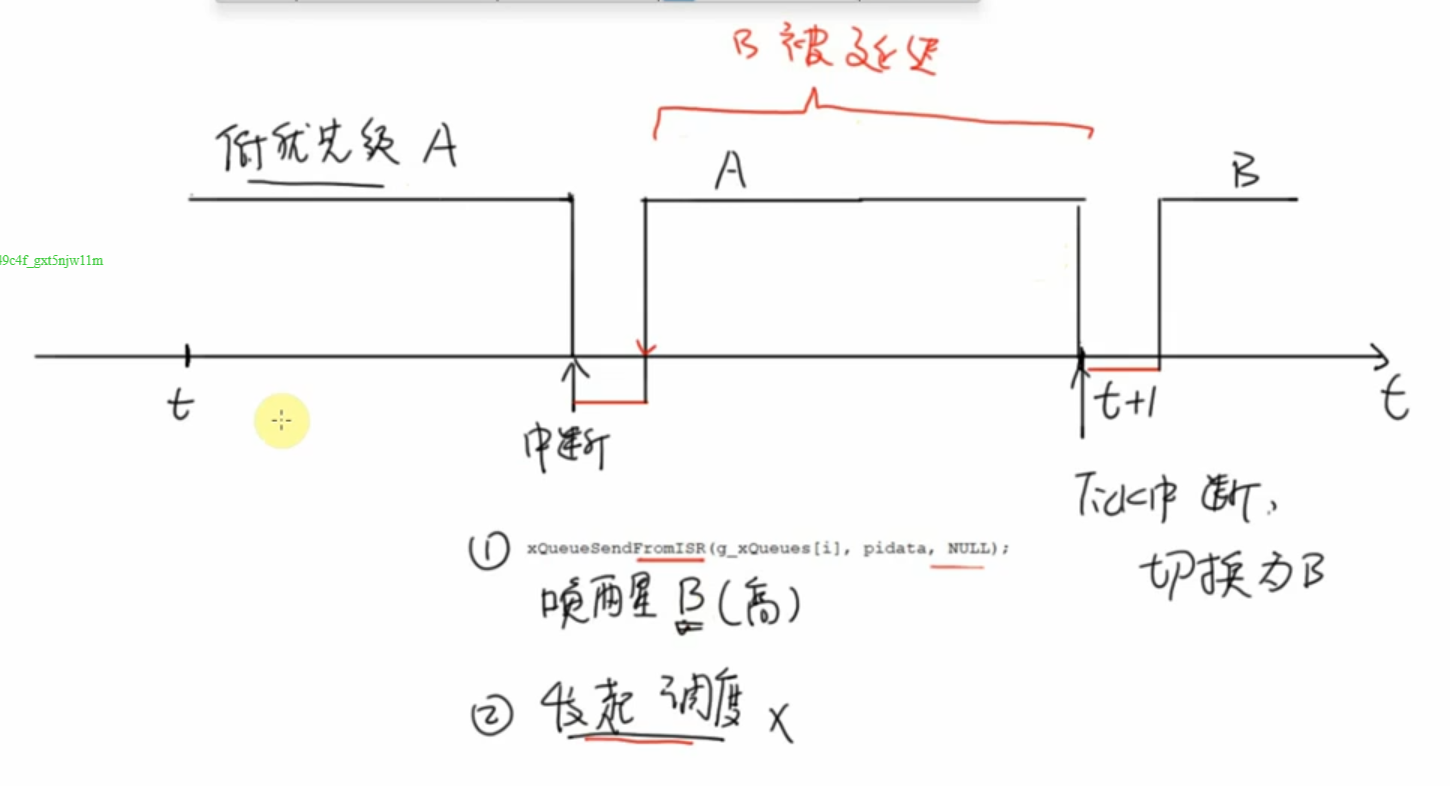
1 | static void DispatchKey(struct ir_data *pidata) |
对应的,把MPU6050和旋转编码器的中断服务函数也修改一下
1 | //void EXTI9_5_IRQHandler() |
资源管理
如何实现互斥操作
屏蔽/使能中断、暂停/恢复调度器。
要独占式地访问临界资源,有3种方法:
- 公平竞争:比如使用互斥量,谁先获得互斥量谁就访问临界资源,这部分内容前面讲过。
- 谁要跟我抢,我就灭掉谁:
- 中断要跟我抢?我屏蔽中断
- 其他任务要跟我抢?我禁止调度器,不运行任务切换
前面学过的队列,事件组,任务通知,信号量互斥量等等,其freertos内部都实现了互斥操作
eg:进入xQueueSend写队列函数内部一层一层看,最终能发现关中断,从而实现了互斥
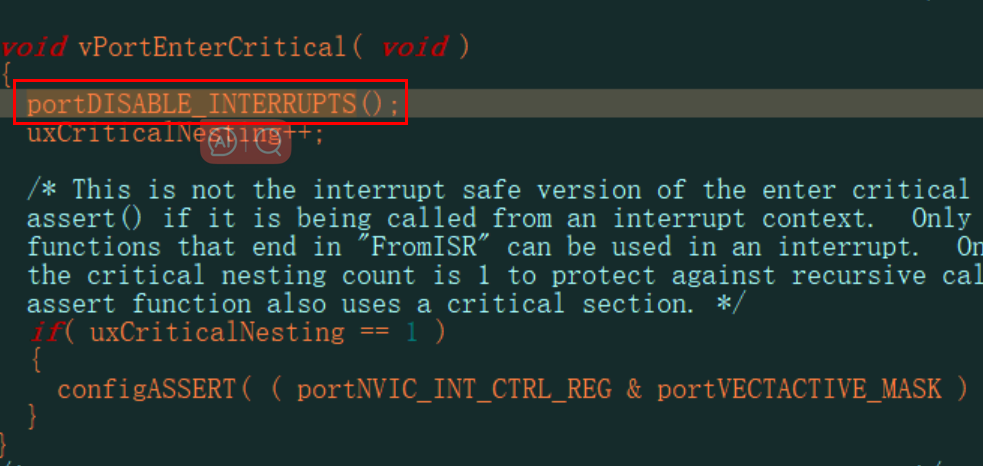
屏蔽中断
屏蔽中断有两套宏:任务中使用、ISR中使用:
- 任务中使用:taskENTER_CRITICA()/taskEXIT_CRITICAL()
- ISR中使用:taskENTER_CRITICAL_FROM_ISR()/taskEXIT_CRITICAL_FROM_ISR()
在任务中屏蔽中断
在任务中屏蔽中断的示例代码如下:
1 | /* 在任务中,当前时刻中断是使能的 |
在 taskENTER_CRITICA()/taskEXIT_CRITICAL() 之间:
低优先级的中断被屏蔽了:优先级低于、等于 configMAX_SYSCALL_INTERRUPT_PRIORITY
高优先级的中断可以产生:优先级高于
configMAX_SYSCALL_INTERRUPT_PRIORITY
- 但是,这些中断ISR里,不允许使用FreeRTOS的API函数
任务调度依赖于中断、依赖于API函数,所以:这两段代码之间,不会有任务调度产生
这套 taskENTER_CRITICA()/taskEXIT_CRITICAL() 宏,是可以递归使用的,它的内部会记录嵌套的深度,只有嵌套深度变为0时,调用 taskEXIT_CRITICAL() 才会重新使能中断。
使用 taskENTER_CRITICA()/taskEXIT_CRITICAL() 来访问临界资源是很粗鲁的方法:
- 中断无法正常运行
- 任务调度无法进行
- 所以,之间的代码要尽可能快速地执行
在ISR中屏蔽中断
要使用含有”FROM_ISR”后缀的宏,示例代码如下:
1 | void vAnInterruptServiceRoutine( void ) |
在 taskENTER_CRITICA_FROM_ISR()/taskEXIT_CRITICAL_FROM_ISR() 之间:
低优先级的中断被屏蔽了:优先级低于、等于 configMAX_SYSCALL_INTERRUPT_PRIORITY
高优先级的中断可以产生:优先级高于
configMAX_SYSCALL_INTERRUPT_PRIORITY
- 但是,这些中断ISR里,不允许使用FreeRTOS的API函数
任务调度依赖于中断、依赖于API函数,所以:这两段代码之间,不会有任务调度产生
暂停调度器
如果有别的任务来跟你竞争临界资源,你可以把中断关掉:这当然可以禁止别的任务运行,但是这代价太大了。它会影响到中断的处理。
如果只是禁止别的任务来跟你竞争,不需要关中断,暂停调度器就可以了:在这期间,中断还是可以发生、处理。
使用这2个函数来暂停、恢复调度器:
1 | /* 暂停调度器 */ |
示例代码如下:
1 | vTaskSuspendScheduler(); |
这套 vTaskSuspendScheduler()/xTaskResumeScheduler() 宏,是可以递归使用的,它的内部会记录嵌套的深度,只有嵌套深度变为0时,调用 taskEXIT_CRITICAL() 才会重新使能中断。
eg:多个函数调用LCD_PrintString函数
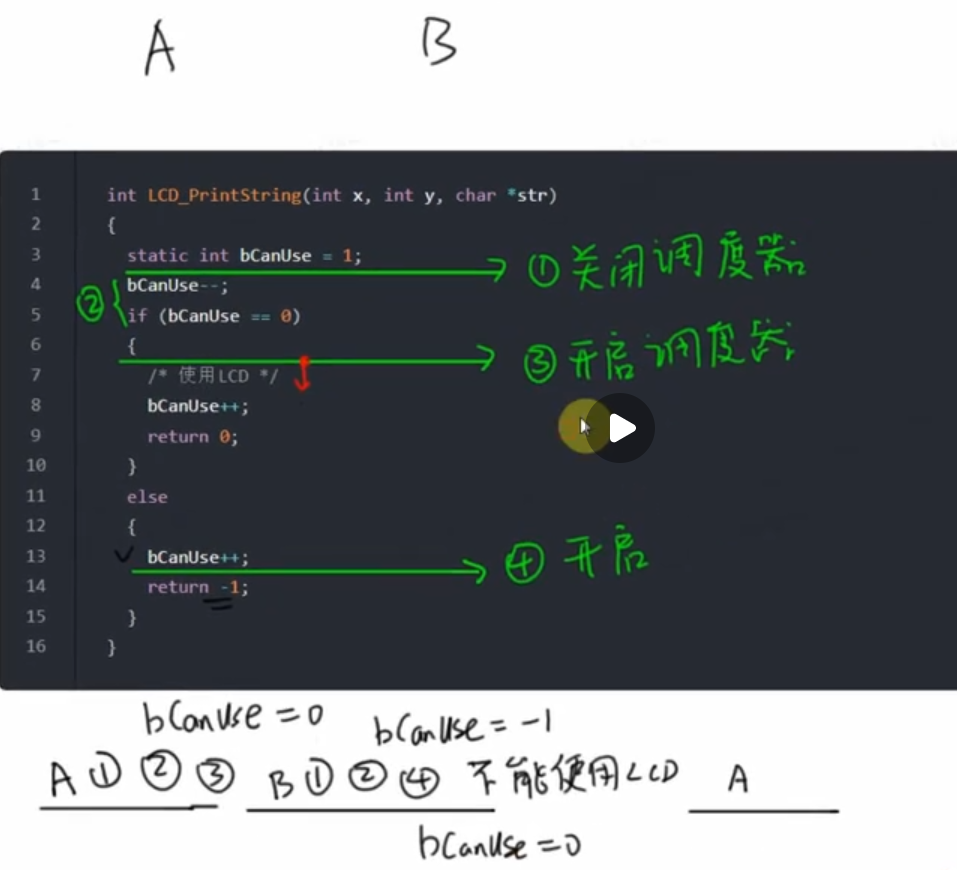
调试与优化
精细调整栈的大小
当我们的程序越来越复杂,会创建很多任务,每个任务都有自己的栈,栈来自堆,当任务越来越多,堆可能就不够用,这时我们要来调整栈,不要让每个任务用的栈非常的大,要精确计算每一个任务用到的栈到底有多大

使用框架
1 | void game1_task(void *params) |

通过串口调试助手可以看到ColorTask的空闲栈还有63,而且这个任务比较简单,后面基本不太可能再加什么复杂的东西,这就很多比较浪费了了,可以设置小一点。
打印所有任务的栈信息
如果在每个任务里添加函数去统计空闲栈有多少,有点麻烦了,我们可以一下子把所有任务的栈都给列出来:
- vTaskList :获得任务的统计信息,形式为可读的字符串。注意,pcWriteBuffer必须足够大。
1 | void vTaskList( signed char *pcWriteBuffer ); |
可读信息格式如下:
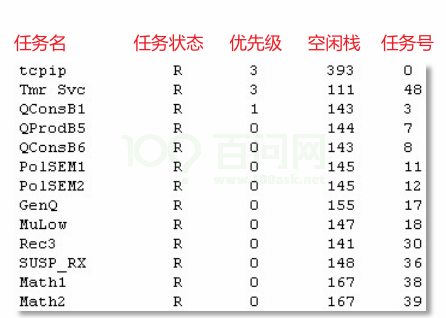
配置流程:
在cubemx中,将其设置为Enable,这样就可以使用vTaskList函数

为了不影响其它任务的运行,我们把它放到freertos的钩子函数中
先在cubemx中使能空闲任务的钩子函数

然后cubemx会在freertos.c生成这个钩子函数,我们把打印代码放进去就行了
1 | freertos.c |
可以看到串口调试助手打印出了相关信息
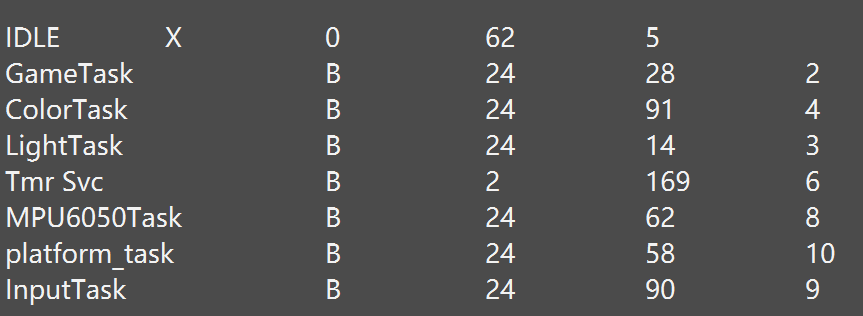
倒数第二列是该行对应任务的空闲栈,感觉大了就可以根据情况调小点
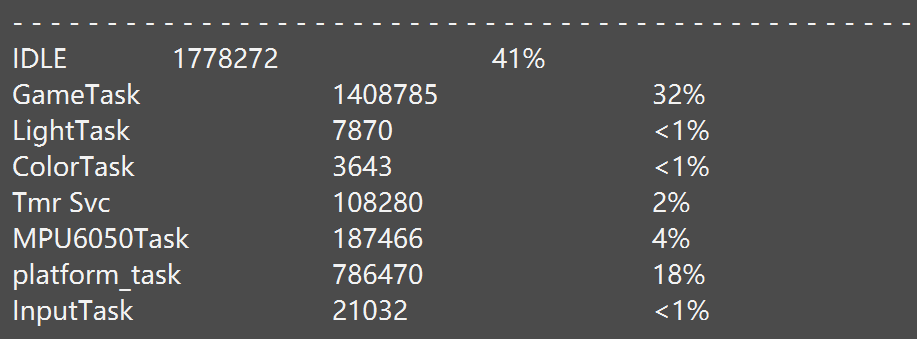
打印任务消耗CPU资源的百分比
统计任务看看它是否非常消耗CPU资源,如果很费CPU资源的话,需要我们去做优化。
介绍
对于同优先级的任务,它们按照时间片轮流运行:你执行一个Tick,我执行一个Tick。
是否可以在Tick中断函数中,统计当前任务的累计运行时间?
不行!很不精确,因为有更高优先级的任务就绪时,当前任务还没运行一个完整的Tick就被抢占了。
我们需要比Tick更快的时钟,比如Tick周期时1ms,我们可以使用另一个定时器,让它发生中断的周期时0.1ms甚至更短。
使用这个定时器来衡量一个任务的运行时间,原理如下图所示:
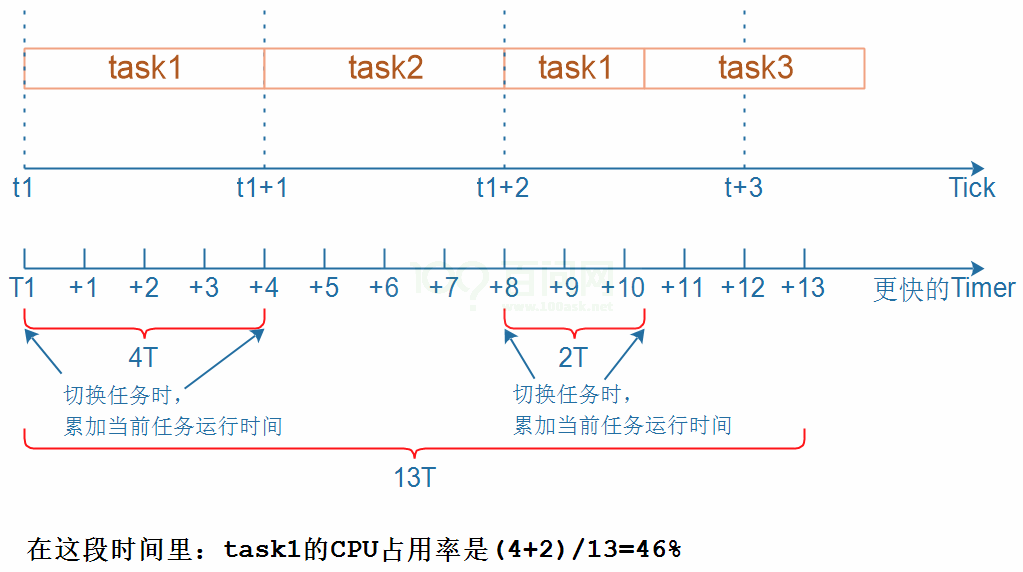
- 切换到Task1时,使用更快的定时器记录当前时间T1
- Task1被切换出去时,使用更快的定时器记录当前时间T4
- (T4-T1)就是它运行的时间,累加起来
- 关键点:在 vTaskSwitchContext 函数中,使用 更快的定时器 统计运行时间
涉及的代码
- 配置
1 |
- 实现宏 **portCONFIGURE_TIMER_FOR_RUN_TIME_STATS()**,它用来初始化更快的定时器
- 实现这两个宏之一,它们用来返回当前时钟值(更快的定时器)
- portGET_RUN_TIME_COUNTER_VALUE():直接返回时钟值
- portALT_GET_RUN_TIME_COUNTER_VALUE(Time):设置Time变量等于时钟值
代码执行流程:
- 初始化更快的定时器:启动调度器时
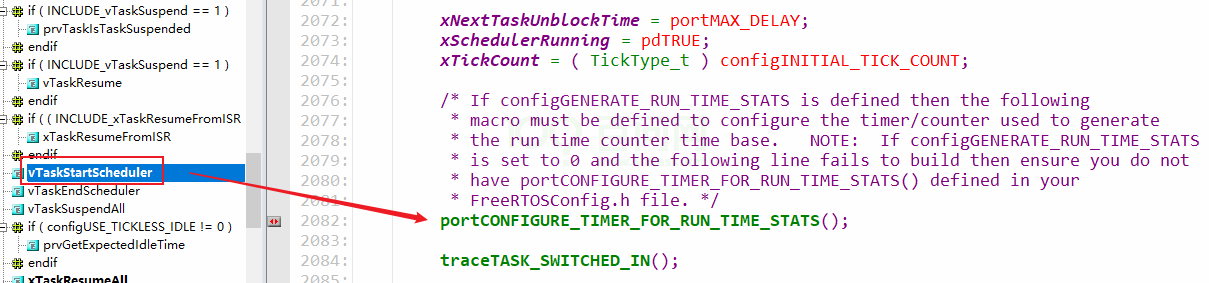
在任务切换时统计运行时间

获得统计信息,可以使用下列函数
- uxTaskGetSystemState:对于每个任务它的统计信息都放在一个TaskStatus_t结构体里
- vTaskList:得到的信息是可读的字符串,比如
- vTaskGetRunTimeStats: 得到的信息是可读的字符串
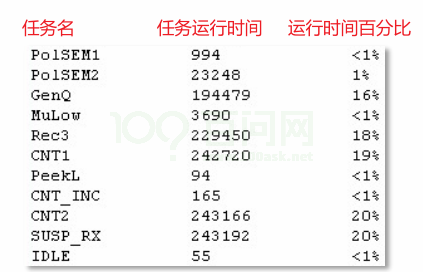
vTaskGetRunTimeStats:获得任务的运行信息,形式为可读的字符串。注意,pcWriteBuffer必须足够大。
1 | void vTaskGetRunTimeStats( signed char *pcWriteBuffer ); |
可读信息格式如下:
配置流程
配置CUBEMX:

然后会生成
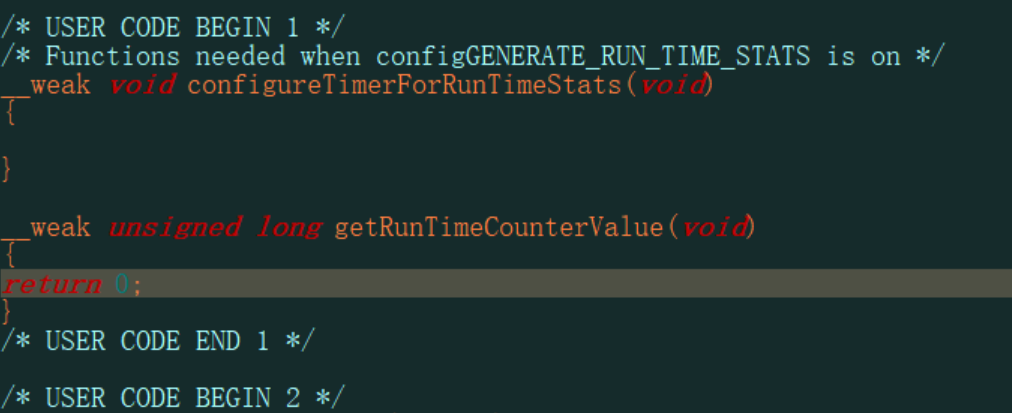
它一直返回0,这是不行的,我们要实现自己的代码
1 | driver_timer.c |
然后在空闲任务的钩子函数里调用vTaskGetRunTimeStats来打印CPU资源的百分比
1 | void vApplicationIdleHook( void ) |
可以从串口调试助手看到MPU6050Task 我们没有晃动板子,但它仍占用了%4的内存,这是不应该的,需要我们对其优化,需要配置陀螺仪的寄存器,把数据就绪中断使能关掉,不然即使没有摇动板子,只要里面的数据就绪就会产生中断。
完结撒花✿✿ヽ(°▽°)ノ✿,后面有时间多看看手册,根据每节课的任务需求,把代码自己再写一遍,做个项目,freertos就可以了,后面就是工作碰到了再补充。
 wechat
wechat alipay
alipay
