
Embedded C language
嵌入式C语言与算法


单片机预备知识
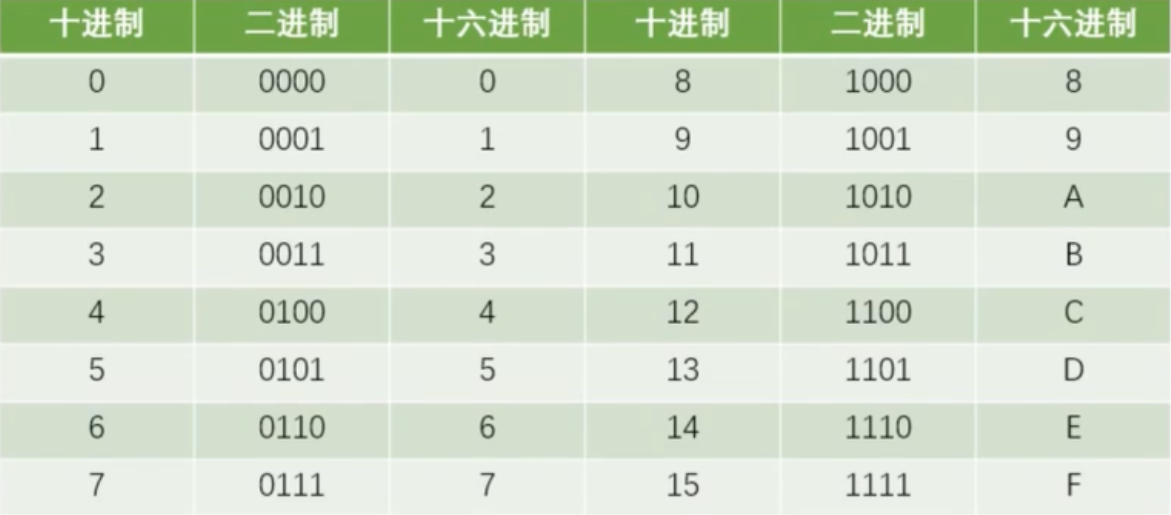
数制
(一)十进制数,ND
数集:0、1、2、3、4、5、6、7、8、9。
规则:逢十进一。
表示:十进制数的后缀为 D 且可以省略。
计算:十进制数可用加权展开式表示。10为基数,10的幂次方称为十进制数的加权数。
(二)二进制数,NB
数集:0、1。
规则:逢二进一。
表示:二进制数的后缀为 B 且不可省略。
计算:二进制数可用加权展开式表示。2 为基数,2 的幂次方称为二进制数的加权数。
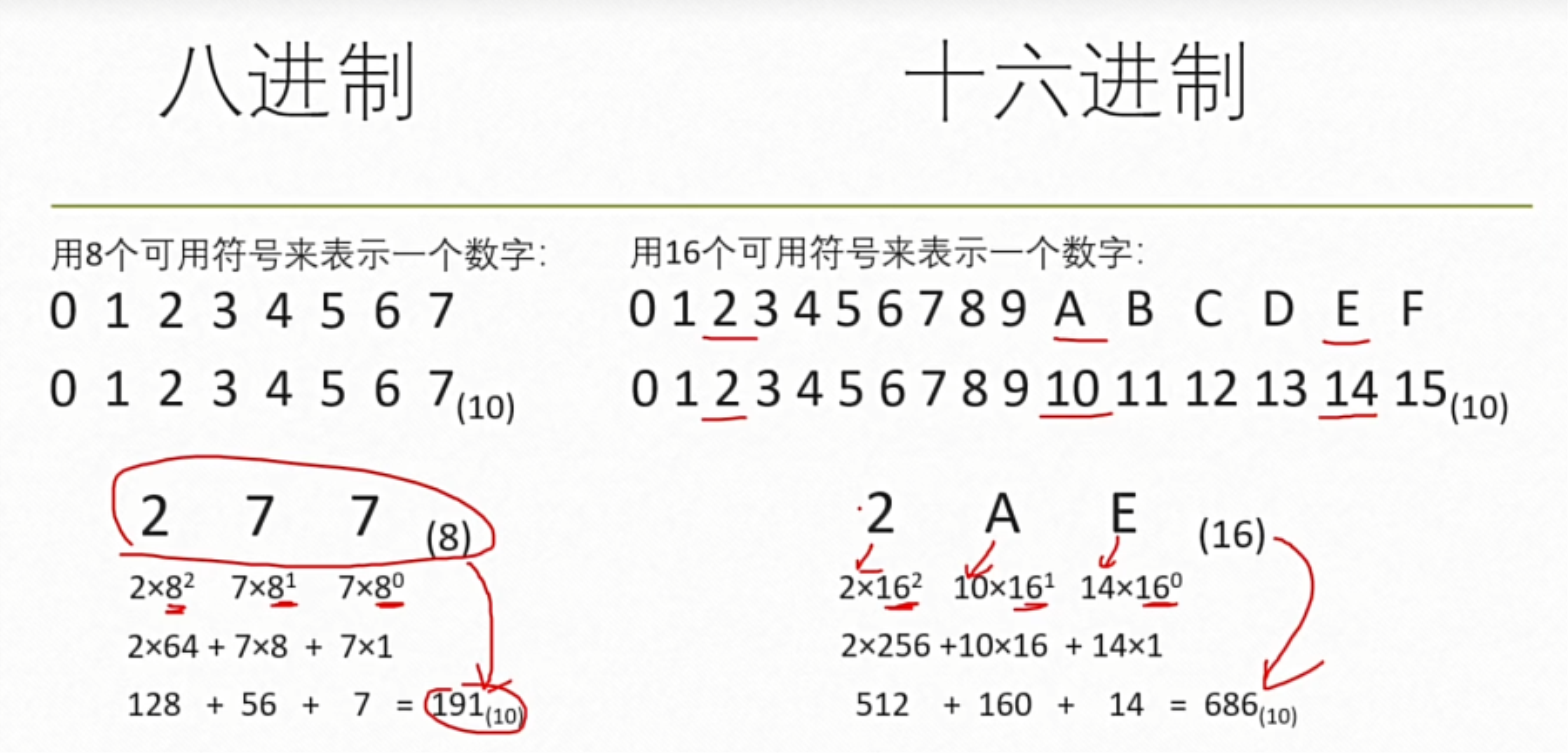
(三)十六进制数,NH
数集:0、1、2、3、4、5、6、7、8、9、A、B、C、D、E、F。
规则:逢十六进一。
表示:十六进制数的后缀为 H 且不可省略。
计算:十六进制数可用加权展开式表示。16 为基数,16 的幂次方称为十六进制数的加权数。
(四)八进制,NO
数集:0、1、2、3、4、5、6、7。
规则:逢八进一。
表示:八进制数的后缀为 O 且不可省略。
计算:八进制数可用加权展开式表示。8 为基数,8 的幂次方称为八进制数的加权数。
进制转换
(一)二、八、十六进制转换为十进制之
利用上述加权展开式计算。

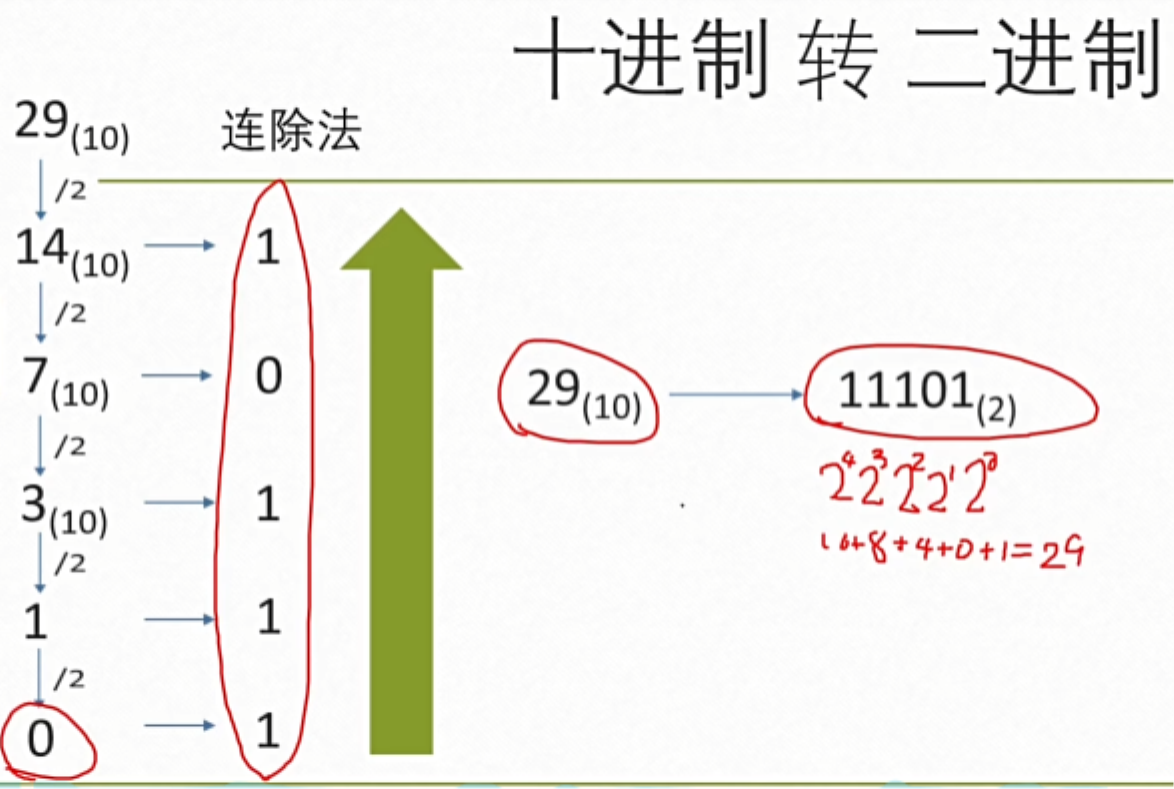
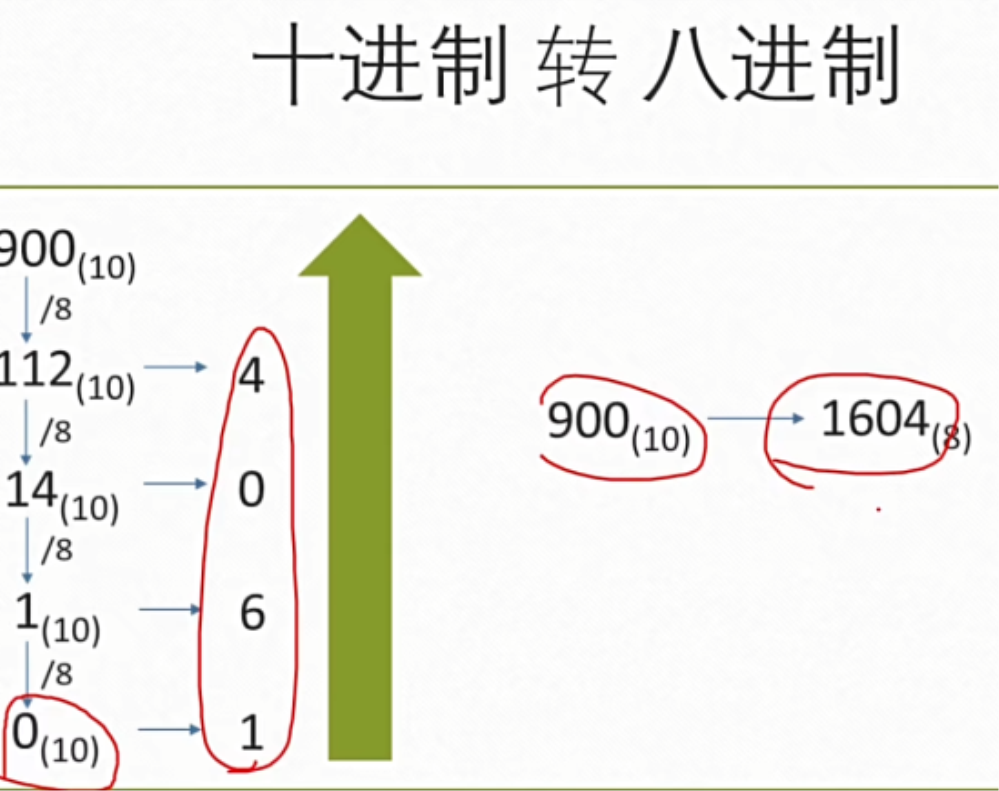
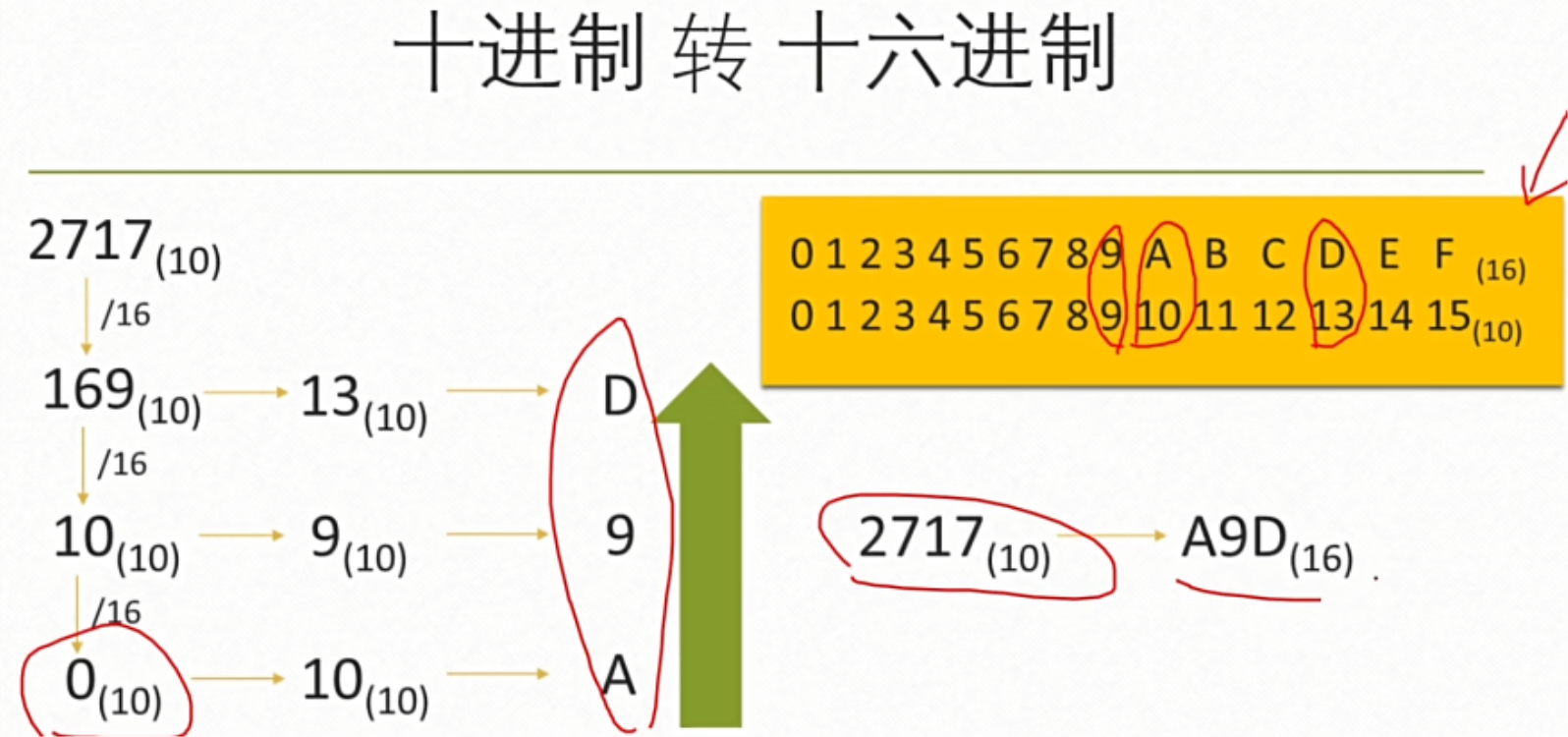
(二)十进制转换为二进制,八进制,十六进制
一般用连除法
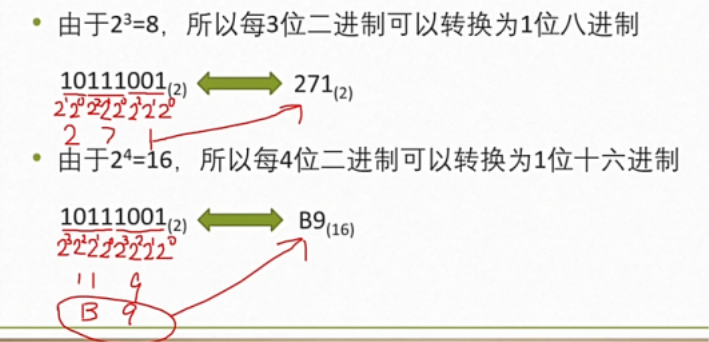
(三)二进制,八进制,十六进制间的相互转换
1.二进制于八进制之间的转换
三位 二进制数 可以表示 一位 八进制数。
36O = 011 110B 111 101 011B = 753O
2.二进制于十六进制之间的转换
四位 二进制数 可以表示 一位 十六进制数。
36H = 0011 0110B 1001 0011 0101 1111B = 935F H
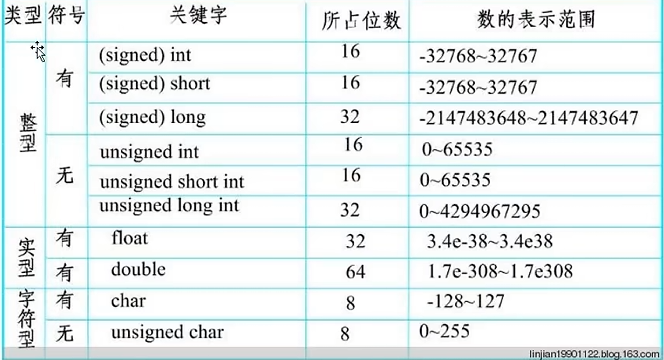
有符号数
实用数据有正数、负数之分,在计算机中用一位二进制数来区分:“0”代表“+”符号,“1”代表“-”符号。
符号位:这位数通常在二进制数中的最高位,称为符号位。
有符号数对应的真实数值称为真值。因符号位占一位,故有符号数的形式值不一定等于其真值。
例如,有符号数0111 1011B(形式值为123)的真值为+123,而有符号数1111 1011B(形式值为251)的真值为-123。
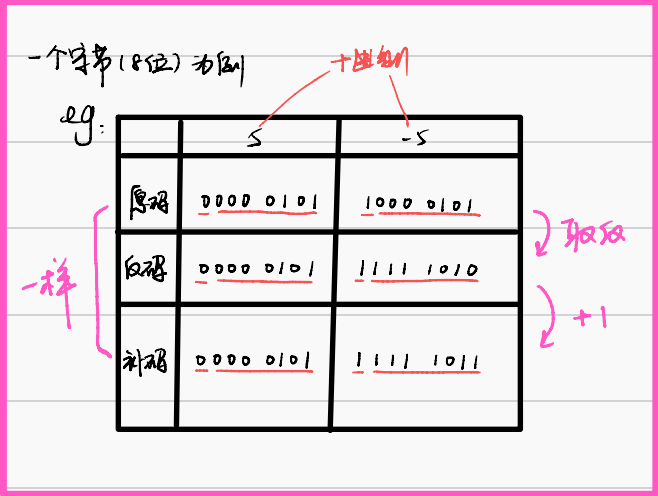
有符号数具有 原码、反码、补码 三种表示法。
原码
有符号数的原始表示法,最高位为符号位,“0”代表“+”符号,“1”代表“-”符号,其余为数值部分。
8位二进制原码范围1111 1111B—0111 1111B(-127—+127)。
对于无符号数 对应的范围是从0000 0000-1111 1111 (0-255 )。

反码
正数的反码与原码相同;
负数的反码,符号位不变,数值部分各位取反。
补码(计算机中都是补码)
正数的补码与原码相同;
负数的补码,符号位不变,反码数值部分加一
有符号数计算时,使用补码进行计算(用原码,反码计算会有错误,补码可以修复这个错误),计算结果再求补,得到最终结果。






位、字节和字
(一)位(bit)b
比特,二进制数中的一位,是计算机内部数据存储的最小单位。
一个二进制位只可以表示 0 和 1 两种状态。
(二)字节(Byte)B
拜特,1 字节由 8 个二进制位构成(1B = 8bit)。是计算机数据处理的基本单位。
B 可代“字节”使用。注意区分二进制数 B 。
KB可代“千字节”使用。 1KB = 1024 B 。64KB = 1024B * 64 = 65536B
(三)字
计算机一次存取、加工和传送的数据长度称为字。
BCD码

ASCII码
计算机中使用的字母、字符要用特定的二进制数表示。
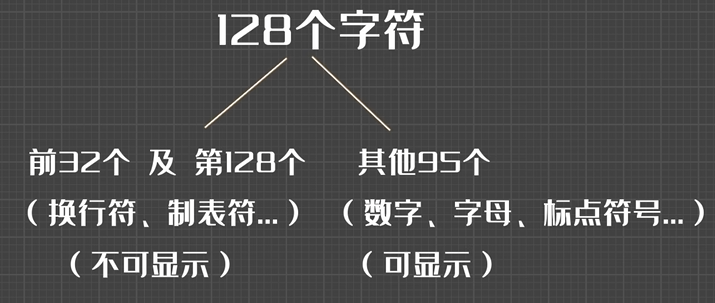
0->48D A->65D a->97D
同一字母大小写相差32D,化为16进制为20H
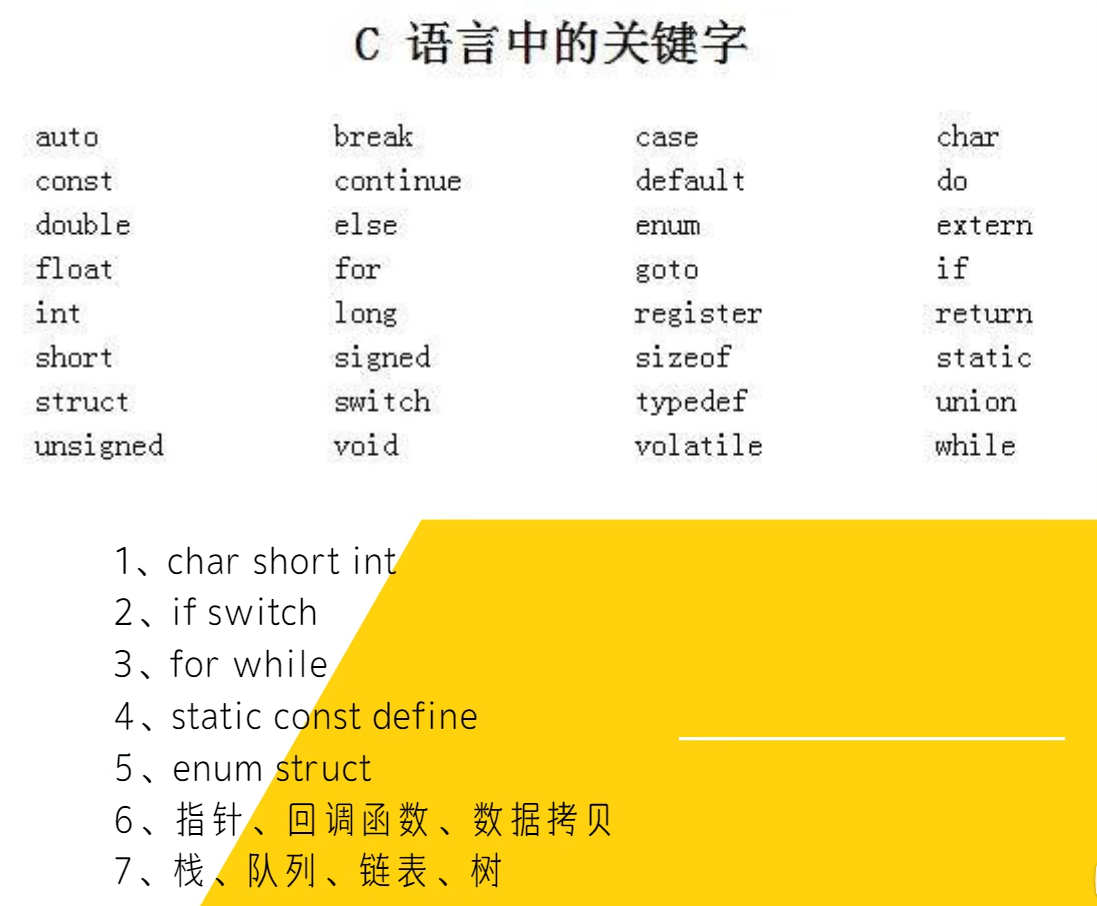
简述C语言中的基础知识
1).数据类型(常用char, short, int , long, signed, unsigned, float, double, sizeof)
2).运算和控制( =, +, -, *, while, do-while, if, else, switch, case, continue, break)
3).数据存储(static, extern, const, volatile)
4).结构(struct, enum, union, typedef)
5).位操作和逻辑运算(<<, >>, &, |, ~, ^)
6).预处理(#define, #include, #if…#elif…#else…#endif等)
1.char short int数据类型
对于单片机开发来说,是至关重要的。因为单片机有8位、16位、32位。如果不注意数据类型,不注意数据长度,那么在编写代码的时候,很容易就会造成数据溢出,导致程序出现bug,而且还很难发现原因。
如果熟悉stm32单片机开发的同学,看官方的例程时,使用的数据类型往往都是重新定义过的类型,很少有直接使用原始数据类型的,比如GPIOIO口设置。
为什么要这样做吗?不嫌麻烦吗?自己平时写程序的时候,往往都是直接使用数据类型的默认名,也依然可以正常使用,没什么问题。但是官方为什么一定要重新定义一次数据类型呢?
个说白了就是大局观的问题,因为官方比我们个人更具有大局观。个人面对的可能也只有几个平台和几款单片机。而官方面对的是多个平台和多种单片机的,这就不得不考虑数据兼容问题了。比如在32位单片机上的算法移植到8位单片机上,代码运行起来后,到处都是数据溢出。要挨个去修改变量的数据类型,那么这时候,作为开发者来说,奔溃不奔溃?抓狂不抓狂?
所以为了解决这个问题,官方就会在每个平台下,给数据类型,重新命名一次,如果需要更换平台,那么只需要替换这个数据重命名的头文件即可。
在32位单片机中int是32位,而在8位单片机中long 才是32位。那么在32位单片机上的int型变量,如果直接移植到8位单片机上的话,那么肯定就会出现数据溢出的问题。
那么如果使用了重命名后的新变量类型 uint32_t ,不论在8位和32位的单片机上,这个数据都会是32位,这样通过数据类型的重定义,就避免了,同样的数据类型,在不同平台上长度不一致的问题。
1 | typedef unsigned char uint8_t; |
不同平台数据类型所占字节对比:
(1个字节有8位)
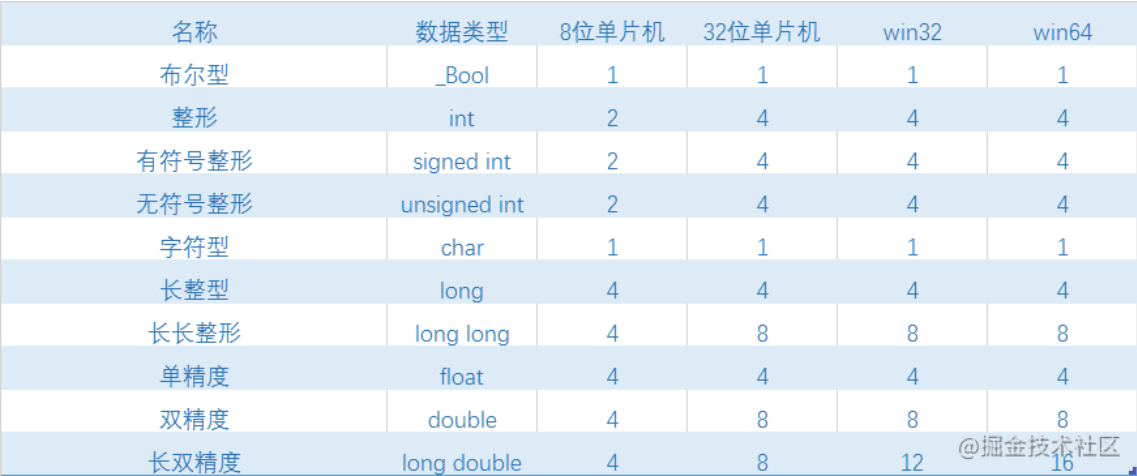
int 即一个装数据的小盒子,对于51单片机(8位单片机),int占两个字节(16位,即16个二进制位),能表示在0~2^16间的数(无符号)
类型转换
见”union共同体”章节
实例应用
1.智能家居:网关协议,mac地址上报?
1 | char *mac="192.168.31.84" |
mac地址如上所示为”192.168.31.84”,为了将其上传到服务器,在定通讯协议时,会和服务器的同事沟通好,收到下面这样一个mac_array数组时,就在每两个数之间加一个小数点来表示mac地址。
即我们将mac地址转化为一个char类型的数组上传到服务器。
提问:为什么mac_array数组的类型用char,而不用int等数据类型?
答:你可以把数据类型当成一个容器来存放数字,只是它们的容量不同,比如
char占用1个字节的内存空间,一个字节有8位,能存放0~255之间的数字,因此char类型很适合表示0-255之间的整数,这个范围完全满足IP地址中每个字段的需求。
如果使用int类型,它通常占用4个字节的内存空间,0-65535,对于用来储存仅需0-255之间的数值而言过于庞大,将浪费大量存储空间,因此在这种情况下,使用char类型更为合适
2.奶茶机器人:温度采集,小数点如何上报云端?
1 | float temp = 37.5; |
服务器发过来unix时间戳 :1607143247,一般是发的hex,即发的是5FCB0F4F,我们接受这串数据,并将其重新解析为时间
5FCB0F4F {0x5F,0xCB,0x0F,0x4F}
1 | unsigned char time_buffer[4]={0x5F,0xCB,0x0F,0x4F};//十六进制的一位等于四位二进制 |
5FCB0F4F {0x5F,0xCB,0x0F,0x4F}
u8Tou32B函数的作用是将一个包含四个字节的unsigned char数组转换成一个unsigned int类型的32位无符号整数,就是把5F,CB,0F,4F拼起来。
继续对上面的u8Tou32B函数进行优化得
1 | unsigned int u8Tou32B_optimized(unsigned char *buffer) |
2.位操作
位,字节,进制
1个字节=8个二进制位
二进制
0b开头,只有0,1,一个字节有8位,该字节能表示的最大数字是把所有位都设置为1:(11111111)=256,因此1字节可储存0~255范围内的数字。
通常unsignedchar 用1字节表示的范围是0255,而signed char 用1字节表示的范围是-128+127.
十六进制
0x开头,用0~15表示数字(0-9,10-15为A-F)
每个十六进制位都对应一个4位的二进制数(即4个二进制位)(2^4=16,即一个四位的二进制数可以表示从0到15的所有整数值),那么两个十六进制位恰好对应一个8位字节。第一个十六进制表示前4位,第2个十六进制位表示后4位
不同类型数据的转换可见union共同体章节
位逻辑运算符
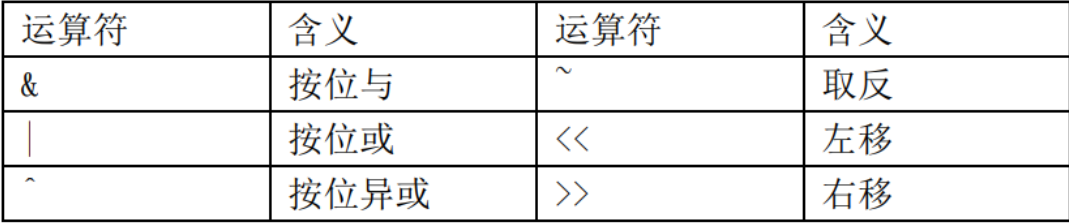
位与&:对于每个位,只有两个对象中相应的位都为1时,结果才为1 &=
(10010011)&(00111101)=(00010001)
常见用法: ch&=0xff(0xff二进制形式是11111111,这个掩码保持ch中最后8位不变,其它位都设置为0)
位或|:只要有一个1就为1 |=
(10010011)|(00111101)=(10111111)
0x20|0x0C=0x2C
位异或^:
取反~:把0变为1,1变为0
在c语言中,!和~均表示取反。
这两个符号的区别在于:
!: 代表逻辑取反,即:把非0的数值变为0,0变为1;- *
~* : 表示按位取反,即在数值的二进制表示方式上,将0变为1,将1变为0。
1 | void TIM0_Init(void) |
掩码
按位与运算符常用于掩码(mask)。所谓掩码指的是一些设置为开(1)或关(0)的位组合
常见用法: ch&=0xff(0xff二进制形式是11111111,这个掩码保持ch中最后8位不变,其它位都设置为0)
移位运算符
左移<<: 将一个运算对象的各二进制位全部左移若干位(左边的二进制位丢弃,右边补0)
(10001010)<<2=(001010000)
右移>>: (10001010)>>2=(00100010)
1.设置或检查特定的标志位
1 | xEventGroupSetBits(g_xEventCar,(1<<1)); |
2.从较大单元中提取一些位
此处可链接到“十六进制”章节中
(每个十六进制位都对应一个4位的二进制数(即4个二进制位)(2^4=16,即一个四位的二进制数可以表示从0到15的所有整数值),那么两个十六进制位恰好对应一个8位字节。第一个十六进制表示前4位,第2个十六进制位表示后4位)
1 |
|
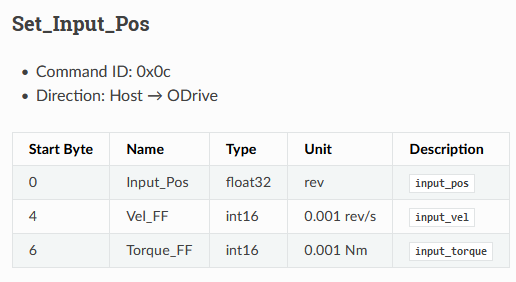
1 | case MSG_SET_INPUT_POS: |
3.数组
float candy[365]; /内含365个float类型元素的数组/
4.结构体struct
基础概念
结构体是 C 编程中另一种用户自定义的可用的数据类型,它允许您存储不同类型的数据项。
结构体中的数据成员可以是基本数据类型(如 int、float、char 等),也可以是其他结构体类型、指针类型等。
关键字–struct, union, typedef
运算符: . ,->
1 | struct xxx(标签,这个结构体的名字) |
1 | //声明结构类型 |
在一般情况下,标签、变量定义,结构变量这 3 部分至少要出现 2 个
tyepedef struct
typedef是类型定义的意思。typedef struct 是为了使用这个结构体方便。
具体区别在于:
若struct node {}这样来定义结构体的话。在申请node 的变量时,需要这样写,struct node n;
若用typedef,可以这样写,typedef struct node{}NODE; 。在申请变量时就可以这样写,NODE n;
区别就在于使用时,是否可以省去struct这个关键字。
1 | typedef struct Student |
例 odrive&stm32驱动代码(可作为使用结构体时的模板)
建立结构声明(模板),定义结构变量
1 | /*odrive.h*/ |
把odrive_set_axis0()声明为一个OdriveAxisSetState_t(在odrive.h定义的结构体)类型的变量
1 | /*odrive.c*/ |
结构的初始化
struct date today={07,31,2014};
结构成员
在C语言中,访问结构体成员时选择使用.或->主要取决于你当前操作的对象是结构体实例本身还是指向该结构体的指针:
•使用.(点号)的情况:当直接操作一个已知的结构体变量时,通过.来访问其内部成员。
1 | struct Student { |
•使用->(箭头)的情况:当操作的是指向结构体的指针时,用->来访问该指针所指向的结构体的成员。
1 | struct Student *stuP; |
简而言之,如果你有一个结构体变量名,就用.;如果你有一个指向结构体的指针,就用->。
结构指针
和数组不同,结构变量的名字不是结构变量的地址,必须使用&运算符
结构与函数
向函数传递结构体的信息:1.传递结构体成员 2.传递结构体地址 3.传递结构
1 | typedef enum |
1 | /*传递结构体地址*/ |
typedef
typedef 在 MDK 用得最多的就是定义结构体的类型别名和枚举类型了。(typedef struct, typedef enum)
利用typedef可以为某一类型自定义名称(为现有类型创建一个名称),它没有创建任何新类型,只是为某个已存在的类型增加了一个方便使用的标签。
1.为经常出现的类型创建一个方便,易识别的类型名。
2.常用于给复杂的类型命名。
1 | //用BYTE表示1字节的数组 |
可以为结体定义一个别名 GPIO_TypeDef,这样我们就可以在其他地方通过别名 GPIO_TypeDef 来定义结构体变量了。
方法如下:
1 | typedef struct |
Typedef 为结构体定义一个别名 GPIO_TypeDef。
1 | GPIO_TypeDef _GPIOA,_GPIOB; |
GPIO_TypeDef 就跟 struct _GPIO 是等同的作用了
enum枚举
enum枚举是 C 语言中的一种基本数据类型,它可以让数据更简洁,更易读。(一个被命名的整形常数的集合 )
枚举类型通常用于为程序中的一组相关的常量取名字,以便于程序的可读性和维护性。
1 | enum 枚举名 {枚举元素1,枚举元素2,……}; |
我们举个例子,比如:一星期有 7 天,如果不用枚举,我们需要使用 #define 来为每个整数定义一个别名:
1 |
声明枚举类型
1 | enum DAY |
枚举变量的定义
我们可以通过以下三种方式来定义枚举变量
1、先定义枚举类型,再定义枚举变量
1 | enum DAY |
2、定义枚举类型的同时定义枚举变量
1 | enum DAY |
3、省略枚举名称,直接定义枚举变量
1 | enum |
typedef enum
是不是感觉和enum没什么区别,确实在一般的使用中两个的结果是差不多的。
但是如果你想定义一个和DAY类型一样的集合的情况下,使用typedef enum更方便
1 | 举例子: |
和
1 | typedef enum DAY { MON=1, TUE, WED, THU, FRI, SAT, SUN }DAY_TYPE; |
(此处用法与typedef struct一样)
枚举(enum)成员的值默认是整型,并且从0开始递增。虽然枚举类型本身不直接支持十六进制的声明方式,但你可以手动为枚举成员赋值,这个值可以是任何整数常量,当然包括十六进制表示的整数
例:
1 | typedef enum |
1 | //enum枚举常用于状态表示 |
5.指针
指针偏移
指针可以作为数组用,数组号表示指针基地址偏移,很多代码都这么用的。
1 | void test(unsigned char *buffer) |
第16行,memcpy函数从packet[1]的地址开始复制,数据依次复制到packet[1],packet[2],packet[3],packet[4]中
1 | void floatToBytes(float val, uint8_t* bytes) { |
函数指针
所谓函数指针即定义一个指向函数的指针变量
1 | int (*p)(int x, int y); //注意:这里的括号不能掉,因为括号()的运算优先级比解引用运算符*高 |
这个函数的类型是有两个整型参数,返回值是个整型。对应的函数指针类型:
1 | int (*) (int a, int b); |
对应的函数指针定义:
1 | int (*p)(int x, int y); //参数名可以去掉,并且通常都是去掉的。这样指针p就可以保存函数类型为两个整型参数,返回值是整型的函数地址了。 |
我们一般可以这么使用,通过函数指针调用函数:
1 | int maxValue (int a, int b) { |
应用案例
1 | typedef struct |
1 | FSM_t FSM ; |
在C语言中,void (*enter)(void);、void (*run)(void); 和 void (*exit)(void); 这三个成员是函数指针类型。
具体解释如下:
void (*enter)(void);1
2
3
4
5
这是一个指向无参数且返回值为 void 的函数的指针。在结构体 FSM_t 中,它表示一个函数指针,当 FSM(有限状态机)进入某个状态时,可以通过调用这个函数指针指向的函数来执行相应的“进入”动作。
2. ```c
void (*run)(void);
同样是一个指向无参数且返回值为 void 的函数的指针。在状态机中,当处于某个状态并需要运行该状态的行为或处理逻辑时,可以调用这个“run”函数指针指向的函数。
void (*exit)(void);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
依然是一个函数指针,指向无参数且返回值为 void 的函数。当 FSM 状态机从当前状态退出时,会调用这个“exit”函数指针指向的函数,用于执行离开状态时所需的动作或清理工作。
因此,在实现一个基于此结构体的状态机时,你需要为每个状态分别定义对应的 enter、run 和 exit 函数,并将它们的地址赋给相应状态的 FSM_t 结构体实例中的这三个函数指针成员。
在C语言中,结构体(struct)可以包含各种数据类型,包括**基本数据类型、指针类型**等。在这个特定的FSM_t(有限状态机)结构体定义中,使用函数指针的主要原因是为了实现灵活且可扩展的设计。
1. 灵活性:***通过将函数作为成员变量(以指针形式存在),可以在不同的实例中为这些函数赋予不同的具体实现,使得状态机的行为可以根据需求动态改变。***
2. 扩展性:在设计模式上,这种方式符合面向对象编程中的“多态”思想。***每个状态可以有自己的enter、run和exit行为,只需要提供相应的函数实现即可。***
3. 解耦合:函数指针将函数的具体实现与结构体(状态机)的定义解耦合,使得状态机的定义更简洁,逻辑更清晰,也方便后期维护和扩展。
4. 高效性:虽然使用函数指针调用会引入一次间接寻址,但在很多情况下,这并不会对性能造成显著影响,而带来的设计优势远大于此微小的性能损耗。总结一下,这里使用函数指针而非直接定义函数,主要是为了构建一个更加灵活、可扩展、高内聚低耦合的状态机模型。
在C语言中,结构体(struct)不能直接包含函数。函数在C语言中不是一种数据类型,因此无法像变量那样存储在结构体中。但是,可以通过存储函数的指针来达到类似的效果,就像上述FSM_t结构体中的enter、run和exit成员那样。
所以,准确地说,结构体内不能直接定义函数,但可以存储函数的地址,即函数指针,间接实现调用关联函数的功能。
#### 回调函数
应用:
1.*送餐机器人:底盘移动到目标位置后,通知应用程序*
2.*智能音箱:网络状态改变后,通知应用程序*
3.*四足机器人项目FSM状态机也有用到回调函数的思想*
```c
//工具代码
typedef struct{
int status;
void (*statusChange)(); //存储后续要调用的回调函数地址
}T_Device;
T_Device g_ Device;
/*
名称:回调函数
作用:将传入的用户函数的地址赋给g_Device.statusChange,当满足条件时,执行该用户函数
*/
//void (*pstatusChange)(int status) 定义了一个指向函数的指针变量 pstatusChange,该函数没有返回值,并且接受一个整型参数 status。
void addCallbackFunc(void (*pstatusChange)(int status)){//将函数的地址传入并赋给g_Device.statusChange,这样g_Device.statusChange指向函数的入口地址
g_Device.statusChange = pstatusChange ;
}
void run(){
g_Device.status = 10;
if(g_Device.status == 10){
if(g_Device . statusChange != NULL){
g_Device.statusChange(g_Device.status);//callBack(10);
}
}
}
//用户代码
void callBack(int status ){}
printf("callBack\n");
printf("status = %d\n" ,status);
}
void main()
{
addCallbackFunc(callBack);//将 `callBack` 函数的地址作为参数传递给了 `addCallbackFunc` 函数,
run();
}
在 main 函数中调用 addCallbackFunc(callBack); 时,发生了以下事件:
callBack是用户定义的一个函数,其原型为void callBack(int status)。- 当调用
addCallbackFunc(callBack)时,将callBack函数的地址作为参数传递给了addCallbackFunc函数。 - 在
addCallbackFunc函数内部,这个传入的参数pstatusChange被赋值给全局变量g_Device的成员statusChange,即g_Device.statusChange = pstatusChange;。因此,现在g_Device.statusChange指向了callBack函数的入口地址。 - 这样一来,就实现了回调函数的注册。当设备状态改变且满足触发条件时(如在
run函数中),可以通过调用g_Device.statusChange(g_Device.status);来执行callBack函数,并将设备状态作为参数传递进去,从而实现对状态变化的响应和处理。
提问:为什么不能直接用if(g_Device.status==10),而非要用回调函数,这是多此一举吗
使用回调函数并不一定是在做无用功,它在某些情况下具有以下优点:
- 解耦合:通过回调函数,我们可以将处理状态变化的逻辑从设备状态管理代码中分离出来。这样可以使代码结构更加清晰,也更容易维护和扩展。例如,在本例中,具体的设备状态改变后的处理行为(即
callBack函数中的内容)可以由用户自定义,而不是硬编码在run函数里。 - 灵活性:当设备状态改变时,不同的应用程序可能需要执行不同的操作。使用回调函数允许我们在运行时动态地根据需要来指定要执行的操作,增加了程序的灵活性。
- 事件驱动编程:回调函数是事件驱动编程模型的重要组成部分。在这种模式下,当某个特定事件(如设备状态改变)发生时,系统调用预先注册好的回调函数,而非直接在触发事件的地方编写处理逻辑。
所以,并不是多此一举,而是为了实现更灵活、解耦的软件设计和开发。当然,在简单场景下,如果状态改变后的处理逻辑固定且无需复用,直接写在if(g_Device.status==10)判断后也是可行的,但在复杂项目或者需要扩展性的情况下,回调函数就显得尤为重要了。
void 修饰指针使用规则
void *
void 指针可以指向任意类型的数据,就是说可以用任意类型的指针对 void 指针对 void 指针赋值。例如:
1 | int *a; |
void 指针可以任意类型的数据,可以在程序中给我们带来一些好处,函数中形为指针类型时,我们可以将其定义为 void 指针,这样函数就可以接受任意类型的指针。如:
void * memcpy(void *dest, const void *src, size_t len);
void * memset ( void * buffer, int c, size_t num );
这样,任何类型的指针都可以传入 memcpy 和 memset 中,这也真实地体现了内存操作函数的意义,因为它操作的对象仅仅是一片内存,而不论这片内存是什么类型。
6.常见关键词
define宏定义关键词
语法:#define 标识符 字符串
“标识符”为所定义的宏名
“字符串”可以是常数、表达式、格式串等
#define SYSCLK_FREQ_72MHz 72000000
ifdef 条件编译
当满足某条件时对一组语句进行编译,而当条件不满足时则编译另一组语句。
1 |
|
作用是:当标识符已经被定义过(一般是用#define 命令定义),则对程序段 1 进行编译,否则编译程序段 2。 其中#else 部分也可以没有,即:
1 |
|
extern变量声明
在一个文件中定义的全局变量,如果在其它文件里想使用,需要在前面加上extern
static关键字
有时候,我们希望函数中局部变量的值在函数调用结束之后不会消失,而仍然保留其原值。即它所占用的存储单元不释放,在下一次调用该函数时,其局部变量的值仍然存在,也就是上一次函数调用结束时的值。这时候,我们就应该将该局部变量用关键字 static 声明为“静态局部变量”。
静态变量的作用:保持变量内容的持久性
1 |
|
在该代码中,我们通过在 count() 函数里声明一个静态局部变量 num 来作为计数器。因为静态局部变量是在编译时赋初值的,且只赋初值一次,在程序运行时它已有初值。以后在每次调用函数时就不再重新赋初值,而是保留上次函数调用结束时的值。这样,count() 函数每次被调用的时候,静态局部变量 num 就会保持上一次调用的值,然后再执行自增运算,这样就实现了计数功能。同时,它又避免了使用全局变量。
1 | static inline void FSM_ChangeState() |
在C语言中,当一个函数前加上 static 关键字时,意味着该函数具有内部链接性(internal linkage),即该函数的作用范围被限制在当前编译单元内。对于这个函数而言,这意味着只有定义它的源文件以及包含它所在的头文件的其他源文件可以访问此函数,不会成为外部全局符号,从而避免不同编译单元之间产生符号冲突。
const关键字
程序开发人员可以在变量定义后,在程序的其他位置引用和修改变量。但程序中定义的一些变量,如圆周率PI=3.14,黄金分割比例 g=0.618,这些变量只需要被引用,不应该被修改。C语言中可以使用 const关键字修饰变量。
1 | const float pi = 3.141592612; |
__IO(volatile)
volatile的含义为 允许硬件改变变量的数值 。告诉编译器不要优化这些代码
volatile 形变量可以被硬件改变,在需要硬件改变变量的场合中不可或缺!!

1 | __IO uint16_t ADC_ConvertedValue; // 用于保存转换后的ADC值 |
例:
1 | static struct TaskPrintInfo g_Task1Info = {0, 0, "Task1"}; |
没有加volatile时,经过debug,发现程序一直会卡LcdPrintTask的while (g_calc_end == 0);处,尽管在debug时显示g_calc_end为1还是一直卡在那里。这是因为在编译器做了一些优化,第一次使用这个变量时,它会去读内存,把这个变量的值读进CPU的某个寄存器,以后在任务2的那个while循环里,它一直都是去判断那个寄存器,但是那个寄存器得到的是这个变量原始的,老的值,它并没有每次都去内存里面读这个变量,更新那个寄存器,这是不对的,因为这个变量,是在其他任务里面被修改了,你去使用这个变量时,每次都应该去读内存,怎么办呢,在变量前加一个volatile就好了,告诉编译器,不要去优化它。
“在多任务环境下,编译器通常会对变量进行优化以提高代码执行效率。当一个变量被标记为 volatile 时,它告诉编译器这个变量的值可能在程序控制范围之外发生变化(例如由中断服务程序、硬件操作或者其他并发任务修改),因此每次访问该变量时都会从内存中重新读取。编译器对变量的优化通常基于以下几种情况:
局部性原理:编译器假设在一段连续执行的代码中,如果一个变量没有被显示地修改(比如通过赋值、函数调用或指针间接访问),其值就不会改变。因此,在循环内多次读取同一变量时,编译器可能会将该变量从内存加载到寄存器中,并在整个循环期间使用寄存器中的值,以减少对内存的访问。
数据流分析:编译器会进行数据依赖性分析,如果它能确定某个变量在当前作用域内不会受外部因素影响而改变,即使这个变量是全局的,也可能对其进行优化。
跨函数优化:编译器还可能进行跨函数优化,例如当函数没有明确的副作用或者编译器能够推断出函数内部对全局变量的修改不会影响到当前上下文时,也会选择不重新加载变量。”
应当在以下情况下考虑使用
volatile关键字来修饰变量:- 变量可能被中断服务程序修改。
- 变量位于多线程环境且不同线程间共享并修改该变量。
- 变量与硬件寄存器映射相关,硬件可能会在软件不可见的情况下更改它们的值。
- 变量用于信号量、事件标志或其他同步机制。
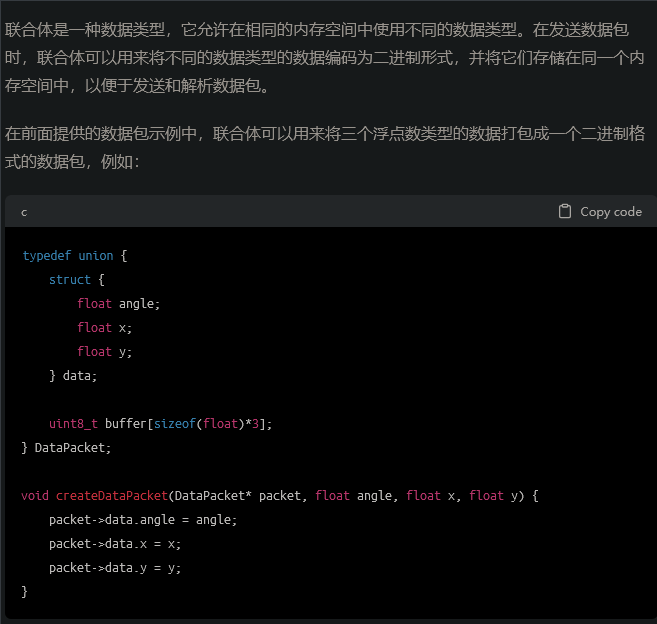
union共同体(联合体)
实现不同类型数据的转换
C语言的union联合体,可实现不同类型数据的转换
结构体和共用体的区别在于:结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。联合体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
简单说就是你给联合体的一个变量赋值,然后表示联合体其中的另一个变量,之前那个赋值了的变量会自动赋给你要表示的这个量,从而实现不同类型数据的转换。

1 | //memcpy函数有三个参数,第一个是目标地址(通常是数组的某一位的地址,即将数据从数组的这一位开始复制),第二个是源地址,第三个是数据长度。 |
memcpy
1 | void *memcpy(void *destin, void *source, unsigned n); |
以source指向的地址为起点,将连续的n个字节数据,复制到以destin指向的地址为起点的内存中。
函数有三个参数,第一个是目标地址(通常是数组的某一位的地址,即将数据从数组的这一位开始复制),第二个是源地址,第三个是数据长度。
数据长度(第三个参数)的单位是字节(1byte = 8bit)。
1 | void floatToBytes(float val, uint8_t* bytes) { |
inline
1 | static inline void FSM_ChangeState() |
1. static:
在C语言中,当一个函数前加上 static 关键字时,意味着该函数具有内部链接性(internal linkage),即该函数的作用范围被限制在当前编译单元内。对于这个函数而言,这意味着只有定义它的源文件以及包含它所在的头文件的其他源文件可以访问此函数,不会成为外部全局符号,从而避免不同编译单元之间产生符号冲突。
2. inline:
inline 关键字提示编译器尝试将函数体直接插入到每个调用该函数的地方(即“内联”),而不是通过正常的函数调用机制(如压栈、跳转等)。这样做的目的是减少函数调用的开销,尤其是当函数体较小且频繁调用时,能够提高程序运行效率。
注意,尽管有 inline 关键字,但是否真正进行内联处理由编译器决定,编译器会根据实际情况判断是否采纳程序员的建议。
综合上述解释,在状态机的上下文中,static inline void FSM_ChangeState() 函数可能用于快速切换状态,由于其内联特性,编译器可能会将状态切换的相关操作直接嵌入到调用处,以提升代码执行速度,并且由于是静态函数,其使用和实现细节被隐藏在当前编译单元内,不对外部模块可见,有助于封装和管理复杂度。
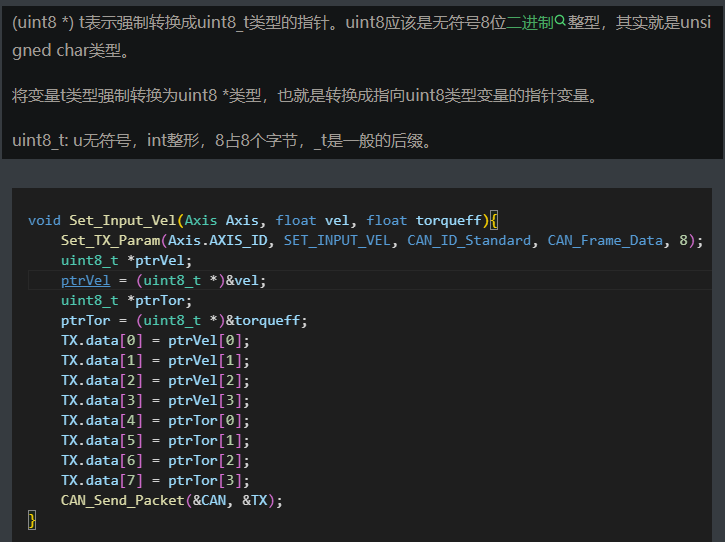
强制类型转换
算法
串口数据包通讯协议
uint8_t packet[14]; //packet数组的一位是一个字节,此packet含14个字节
串口接收鲁棒性高,采用校验帧头、帧尾以及数据长度的方式,确保接收数据的稳定性。
之前一直没用过帧头帧尾,主要是之前用串口传输的数据量都不大,如果要传输多种数据,就需要用帧头帧尾确保数据传输的准确性
(STM32通讯系列–串口通讯】使用标准库、HAL库实现任意长度数据的收发(包含帧头、帧尾校验,配套完整开源程序)
1 | //packet.c |
1 |
|
环形缓冲区
环形缓冲区是嵌入式系统中十分重要的一种数据结构,比如在串口处理中,串口中断接收数据直接往环形缓冲区丢数据,而应用可以从环形缓冲区取数据进行处理,这样数据在读取和写入的时候都可以在这个缓冲区里循环进行,程序员可以根据自己需要的数据大小来决定自己使用的缓冲区大小,不用担心数组越界。
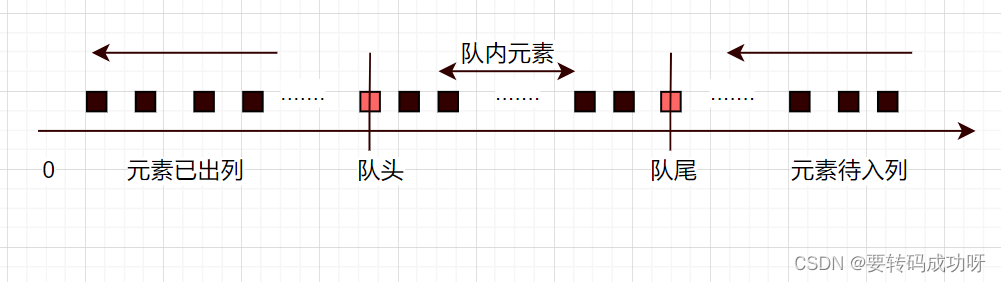
队列的基本概念:队列 (Queue):是一种先进先出(First In First Out ,简称 FIFO)的线性表,只允许在一端插入(入队),在另一端进行删除(出队)。
队列头就是指向已经存储的数据,并且这个数据是待处理的。下一个CPU处理的数据就是1;而队列尾则指向可以进行写数据的地址。
队列是什么
队列是一种很常见的数据结构,满足先进先出的方式,如果我们设定队列的最大长度,那就意味着进队列和出队列的元素的数量实则满足一种动态平衡。
如果我们把首次添加入队列的元素作为一个一维坐标的原点,那么随着队列中元素的添加,坐标原点到队尾元素的长度会无穷无尽的增大,随这之前添入的元素不断出列,对头对应的下标点也在不断增大。这样,进队列和出队列的元素的数量就对应到对头和队尾下标点的移动
因此我们评判一个队列长度是否溢出原先约定的最大长度,实则就是在评判队尾坐标点与队头坐标点之间的差值,无论是出队列还是入队列,队头和队尾的坐标都在不断增大
front指针和rear指针的引入
虽然队尾和队头的下标在不断增大,但是我们对于队列的研究只需要局限在队头与队尾之间的元素,坐标原点到队头之间的元素已经算作出列元素,并不需要研究。因此我们不妨将队列在逻辑上放入一个事先设定容量的一维数组中,只要这个数组的容量是队列中元素的个数+1就行,为什么要这么设定待会再讲。我们想要达到的目的是,无论出列还是入列,本质上是通过修改数组中元素的值,那些已经出列的元素所在的下标位需要放置新入列的元素,并在逻辑上保证新入列元素位于队尾就行。
因此,我们不得不得引入头指针front和尾指针rear,对指针指向的数组下标对应空间进行操作,来修改数组中元素的值。
front指针和rear指针的理解
front:初始值为0,对应索引位待出列,若当前指向的数组下标的元素要出列,则先执行出列动作(实际上不用操作,出列的索引位可以被新入队的元素覆盖),随后front指针就要向后一位,即front++
rear:初始值为0,对应索引位待入列,若当前指向的数组下标有元素要入列,则先执行入列动作(索引位元素赋值),随后front指针就要向后一位,即rear++
队列最大长度匹配数组容量导致一种错误的解决方案
这就会有一个问题,随着队列中元素的不断更迭,front和rear很快就会超过数组容量,造成数组索引越界
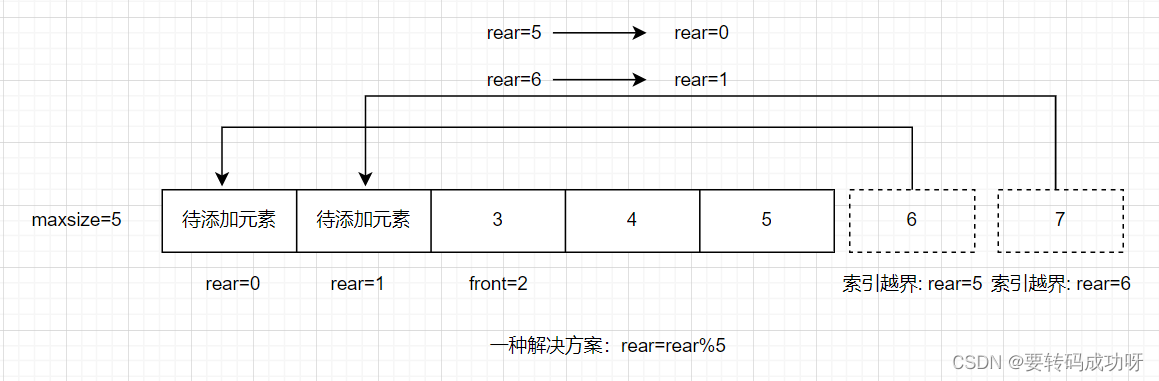
比如上图所示,front=2,也就是说已经有两个元素出列了,因此rear=5与rear=6对应的两个元素理应可以入列,但是我们发现数组maxsize=5,不存在索引位5和6,强行对这两个下标赋值会造成索引越界异常indexOutException 。但是我们发现此时数组中索引位0和1都空着,完全可以将这两个位置利用起来,因此我们可以想办法让实际的rear值转化为等效的rear值,也就是是让rear=5转化为rear=0,同理rear6转化为rear=1。怎么做到呢?无疑是通过取余!
每次新元素入队后, 执行rear=(rear)%maxSize操作,随后执行rear++操作右移rear指针
像上图中的rear=rear%5乍一看好像没问题,但实际上这种取余方式是有问题的,出现这种取余方式的根源在于我们想让队列最大长度与数组容量保持一致,下文会详细说明这种解决方案的错误之处。
指针的往复移动:逻辑上的环形
出队和入队的方向是从右向左,而front与rear指针的移动方向却是从左到右循环往复(指向数组末尾后按照取余算法又重置为数组开头),因此我们可以把单向数组在逻辑上理解成环形数组,指针的循环往复移动理解成按照顺时针或逆时针(只要规定某一方向就好)单向移动
环形队列小知识:
环形队列是在实际编程极为有用的数据结构,它有如下特点。
它是一个首尾相连的FIFO的数据结构,采用数组的线性空间,数据组织简单。能很快知道队列是否满为空。能以很快速度的来存取数据。
因为有简单高效的原因,甚至在硬件都实现了环形队列。
环形队列广泛用于网络数据收发,和不同程序间数据交换(比如内核与应用程序大量交换数据,从硬件接收大量数据)均使用了环形队列。
队列为空的判别
我们怎么判断队列为空呢?
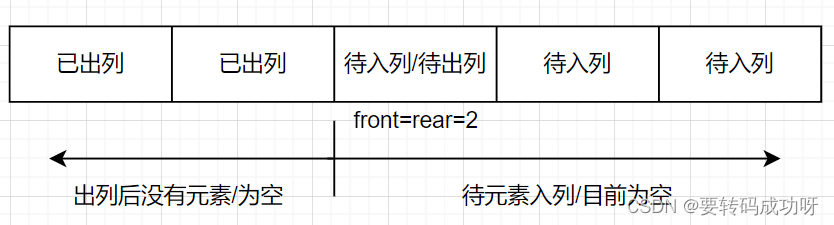
如果我们按照指针从左到右的方向移动,当front指针和rear指针重合时,front指针对应的索引位之前的索引位都已经出列完毕,而rear指针对应的索引位以及之后的所有索引位还未有元素入列。
所以队列是否为空的判别:front==rear
rear=rear%maxSize解决方案的问题
入队图示
下图展示了maxSize=5的数组中,front=0保持不变,元素依次入列直到满载,rear指针的移动情况:
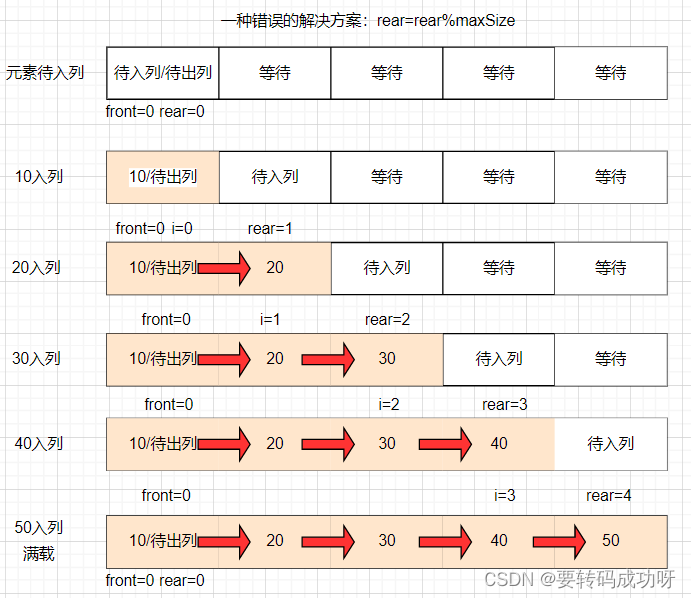
front=rear=0的歧义
可以看到,如果我们认为队列容量与数组容量应该持平,那么当第五个元素50入列后,本来rear=4执行了rear++的操作后,rear=5,随后rear将会通过取余算法rear=rear%maxSize重置为0,这是我们解决方案的核心!
但关键点就在这里,我们发现空载时front=rear=0,满载时依然有front=rear=0!这样子我们就无法判断front=rear时,队列是空还是满,因此rear=rear%maxSize这种解决方案是不被允许的
新的解决方案:置空位的引入
新的解决方案
每次新元素入队后, 执行rear=(rear+1)%maxSize操作,该操作包含rear++操作
置空位的引入
并且我们人为规定,数组中必须留有一个索引位不得放置元素,必须置空!!!如何实现我们的人为规定呢?那就要先探索当数组满载后front和rear指针之间有啥关系
入队图示
下图展示了maxSize=5的数组中,front=0保持不变,元素依次入列直到满载,rear指针的移动情况:
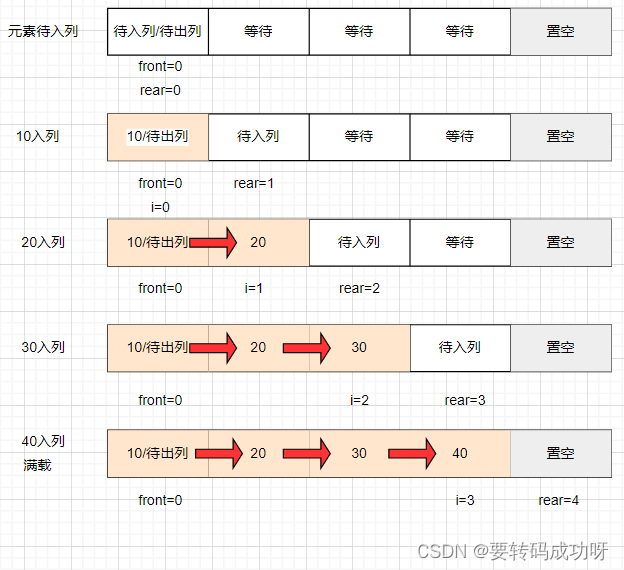
人为的让最后一位置空,所以当元素40入列后,数组已经满载
满载后数据之间的关系:
front=0
rear=(rear+1)%maxSize=(3+1)%5=4 (注: 执行完arr[rear]=40,再执行 rear=(rear+1)%maxSize)
(rear+1)%maxSize=(4+1)%5=0=front
当我们认为的满载发生后,最后一位置空,发现此时rear和front之间的关系为(rear+1)%maxSize=(4+1)%5=0=front,因此这个关系可以作为满载的条件
因为处于满载状态,我们无法再往队列添加元素,只能从队列取出元素,也就是进行出列的操作,而一旦我们执行了出列的操作,比如将索引位i=0上的元素10出列后,则front右移,即执行front=(front+1)%maxSize操作,最终front=1。
若随后又添加元素入列,即在索引位i=4上添加元素50,随后又会执行rear=(rear+1)%maxSize操作,最终rear=0。
rear=0≠front=1,此时就不会出现之前那种错误方案中 rear=front=0导致歧义的情况,而一旦 rear=front=0,必然表示队列为空,因此这种解决方案是行得通的
队列为满的判别
当我们认为的满载发生后,最后一位置空,发现此时rear和front之间的关系为(rear+1)%maxSize=(4+1)%5=0=front,因此这个关系可以作为满载的条件
队列中元素的个数
numValid=(rear+maxSize-front)%maxSize,大家可以带入数据验证一下
实际上:
当rear在front之后(这里指的是数组中索引位的前后,并非逻辑上的前后),有效数据个数=rear-front=(rear+maxSize-front)%maxSize
当rear在front之前(这里指的是数组中索引位的前后,并非逻辑上的前后),有效数据个数=(rear+maxSize-front)%maxSize
值得注意的一些细节
细节1
置空位虽然是人为引入的,但这不意味这置空位的位置是随意的,实际上,只有队列满后才会将剩下的位置作为置空位,一旦置空位出现,rear和front永远不可能指向同一个索引位,因为你会惊奇的发现置空位恰号将rear和front隔开了.
置空位就像一把锁,一旦上锁就只能通过出队列操作解锁
继续执行获取元素操作出队列(解锁):
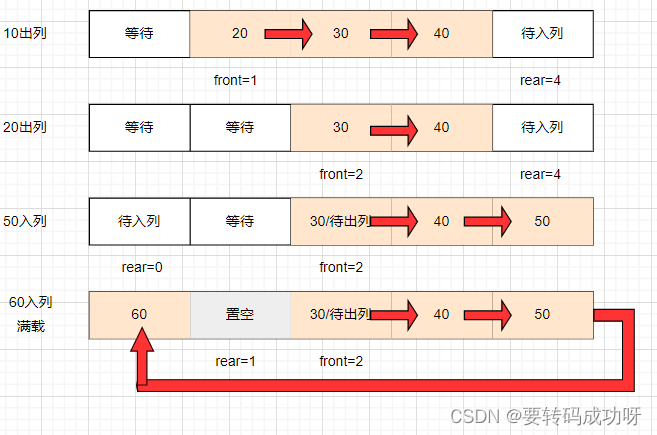
上图中60入列后满载,可以看到置空位再次出现,但30➡40➡50➡60➡置空位 形成了逻辑上的闭环
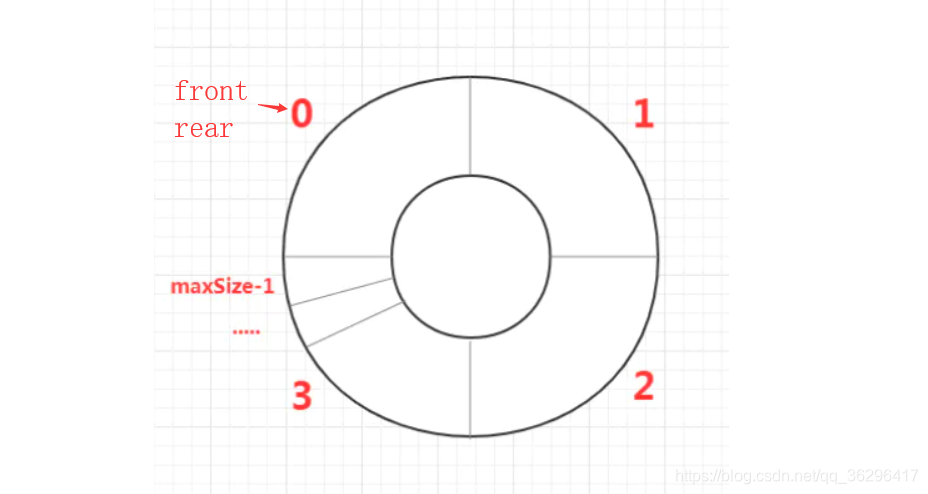
细节2
从闭环的角度理解,front永远不可能在循环中超过rear,最多只能和rear相遇。
因为置空位的出现,rear不可能拉front一圈,也就避免了rear在超过front的情况下主动与front相遇
下图中的maxSize-1对应的就是置空位,rear是无法越过置空位的。只有front主动顺时针追赶上rear,它俩才会相遇,而此时队列内就没有元素,为空
细节3
队列的最大长度queueMaxsize=数组容量arrayMaxSize-1 (由于置空位要占一位)
1 |
|
基于状态机
当“喂一口饭”、“回一个信息”都需要花很长的时间,无论使用前面的哪种设计模式,都会退化到轮询模式的缺点:函数相互之间有影响。可以使用状态机来解决这个缺点,示例代码如下:
1 | // 状态机 |
在main函数里,还是使用轮询模式依次调用2个函数。
关键在于这2个函数的内部实现:使用状态机,每次只执行一个状态的代码,减少每次执行的时间,代码如下:
1 | void 喂一口饭(void) |
以“喂一口饭”为例,函数内部拆分为4个状态:舀饭、喂饭、舀菜、喂菜。每次执行“喂一口饭”函数时,都只会执行其中的某一状态对应的代码。以前执行一次“喂一口饭”函数可能需要4秒钟,现在可能只需要1秒钟,就降低了对后面“回一个信息”的影响。
同样的,“回一个信息”函数内部也被拆分为3个状态:查看信息、打字、发送。每次执行这个函数时,都只是执行其中一小部分代码,降低了对“喂一口饭”的影响。
使用状态机模式,可以解决裸机程序的难题:假设有A、B两个都很耗时的函数,怎样降低它们相互之间的影响。但是很多场景里,函数A、B并不容易拆分为多个状态,并且这些状态执行的时间并不好控制。所以这并不是最优的解决方法,需要使用多任务系统。
FSM状态机
首先初始化FSM状态机,FSM_Init(PASSIVE);
在一个while(1)中运行FSM_Run();
在外部触发条件下使用FSM_SetState( )来设置想切换的模式;此过程中FSM模式变为CHANGE模式(FSM.mode = CHANGE;)
FSM的下一个状态变为FSM.nextState = state;
这样在FSM_Run();中 首先运行FSM.exit(); 即当前的状态的exit函数,然后使用FSM_ChangeState();函数将FSM的进入,运行,退出函数改成要切换的状态所对应的 (每一个状态写一个单独的.c.h文件,然后所有.h文件放到FSM.h中,FSM.c文件直接用FSM.h就行)
1 | FSM.enter = Passive_Enter; |
然后就是该状态的进入函数,此时切换状态这一过程已经结束了,FSM模式变为NOMARL模式,然后运行该状态的运行函数
1 | /*FSM.c*/ |
1 | /*FSM.h*/ |
PID算法
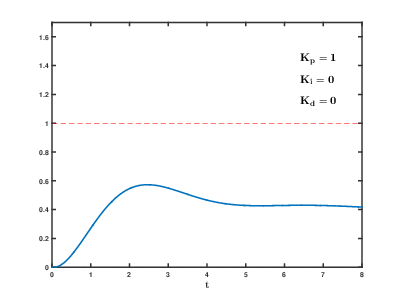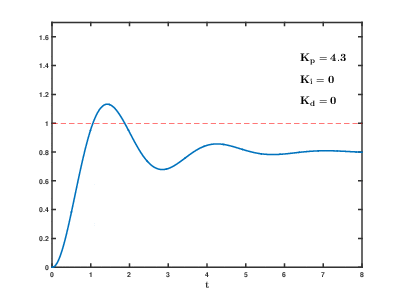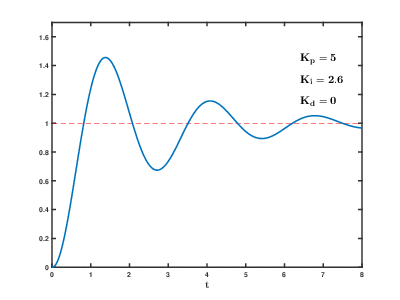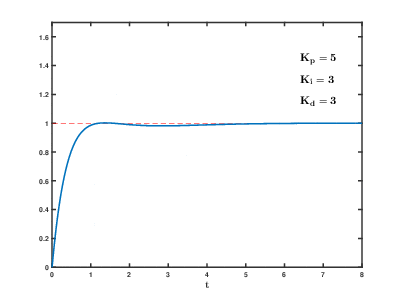
概念
PID,就是“比例(proportional)、积分(integral)、微分(derivative)
它可以将需要控制的物理量带到目标附近
它可以“预见”这个量的变化趋势
它也可以消除因为散热、阻力等因素造成的静态误差
kP
实际写程序时,就让偏差(目标减去当前)与调节装置的“调节力度”,建立一个一次函数的关系,就可以实现最基本的“比例”控制了~
kP越大,调节作用越激进,kP调小会让调节作用更保守。
刚才我们有了P的作用。你不难发现,只有P好像不能让平衡车站起来,水温也控制得晃晃悠悠,好像整个系统不是特别稳定,总是在“抖动”。
kD
阻尼, kD参数越大,向速度相反方向刹车的力道就越强。
KI
设置一个积分量。只要偏差存在,就不断地对偏差进行积分(累加),并反应在调节力度上。
I的作用就是,减小静态情况下的误差(消除稳态误差),让受控物理量尽可能接近目标值。
在使用时还有个问题:需要设定积分限制。防止在刚开始加热时,就把积分量积得太大,难以控制。
使用
需要及时更新数据,一般是写个while循环使用pid_calc,延时几毫秒更新1次
1.DJ
1 |
|
1 |
|
2.电机位置环
1 | /*pid.c*/ |
应用案例
循迹(写的不太好,看看就行)
1 | void app_linewalking2() |
电机位置环
1 | void Pos_ctrl_ML(float rotationNum) |
1 | /*pid.c*/ |
通讯协议
USART
CAN
传感器
编码器
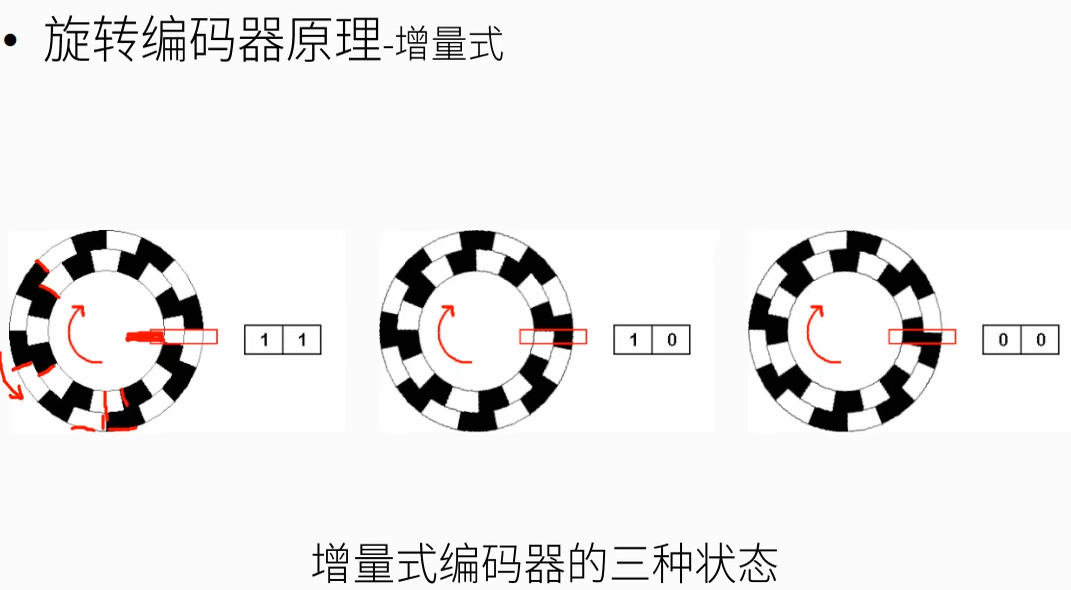
根据编码类型分为增量式,绝对式和混合式。
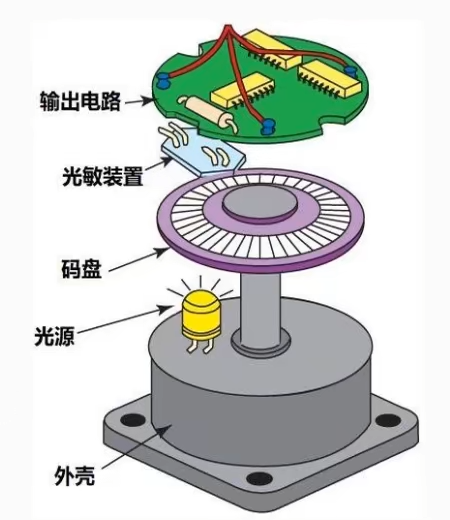
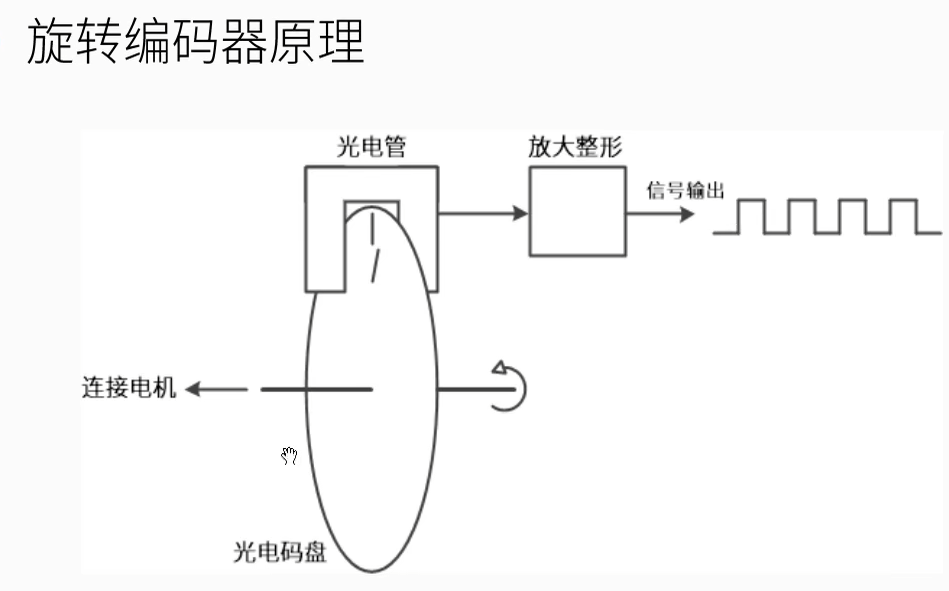

分辨率即线数,即每转一圈输出的脉冲数。

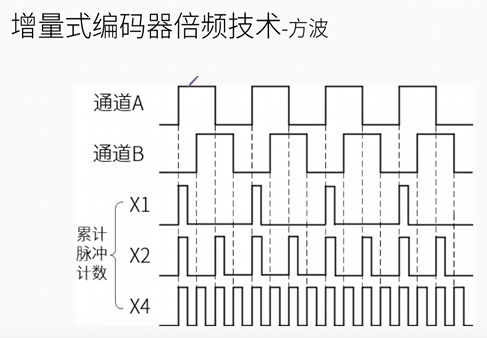
码盘透过光线时,通道A输出1(高电平),通过检测高电平的数量来判断转过的位置,通过检测A和B谁先到高电平来判断运动的方向。若将计数策略从记录高电平转换为记录A上升沿和下降沿,则二倍频。A,B通道相差四分之一周期,若记数A,B的上升沿和下降沿,则在一个周期内可记录四次,即4倍频,将编码器分辨率提高4倍。比如这个编码器的分辨率为1000,最小分辨角度为3.6°,通过四倍频,其分辨率变为4000,最小分辨角度变为0.9°
M法适合高速。

eg: n=8000/(4000*2)=1r/s.
理想状态下测量的脉冲数是整数个,但由于开始测量时有可能处于一个脉冲的任意位置,对于速度很低的情况下,误差比较大,通过4倍频也可以起到减小误差的作用。
T法适合低速。

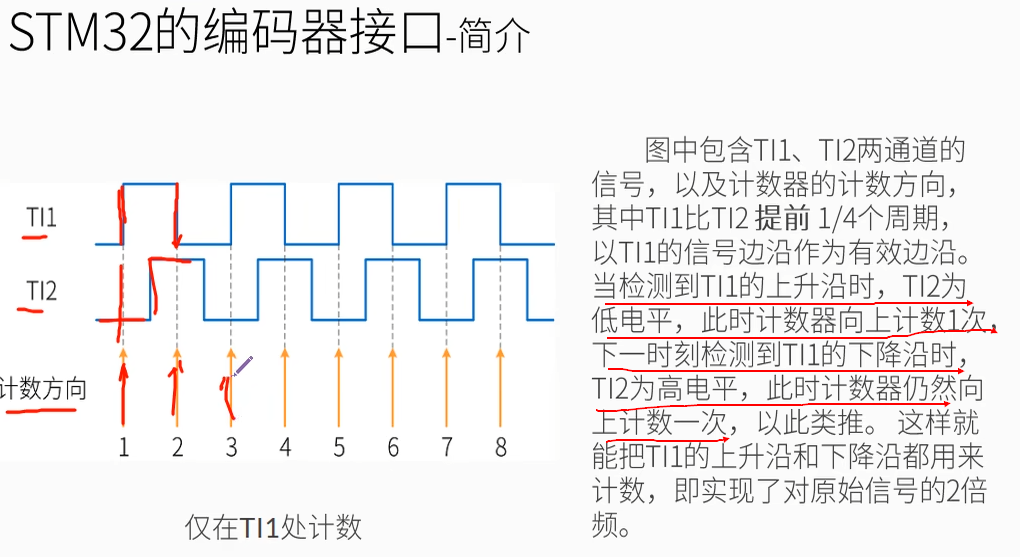
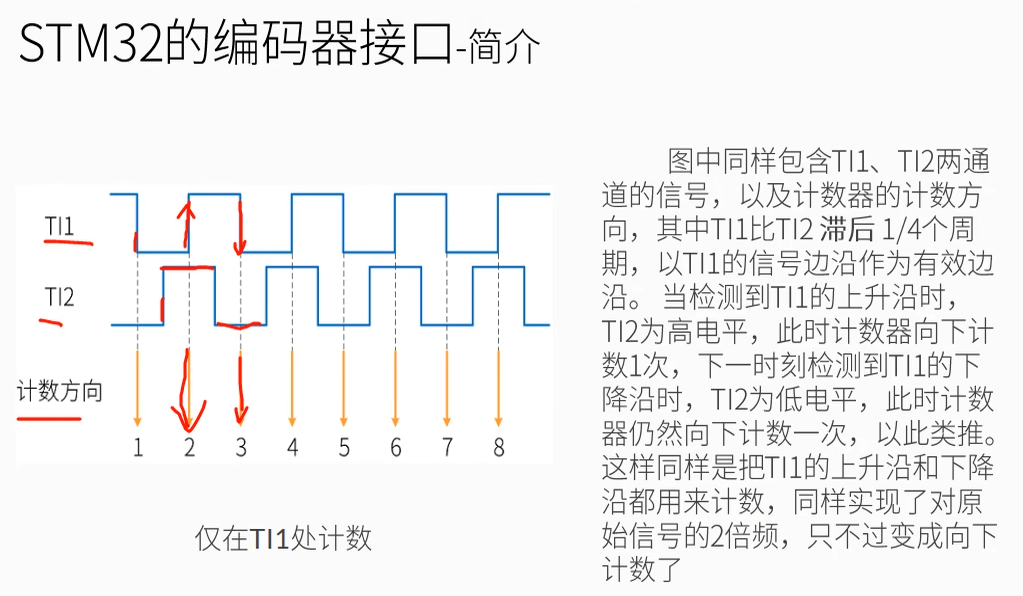
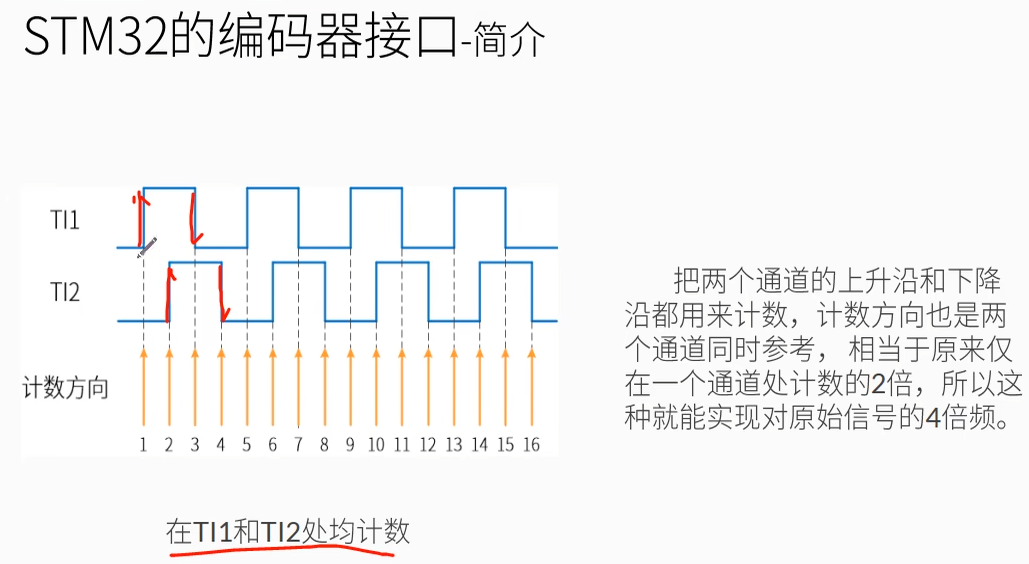
向上计数和向下计数即编码器旋转的方向。
光电
超声波
激光测距
陀螺仪
执行器
PWM
PWM 信号其实就是一高一低的一系列电平组合在一起,若I/O口有集成模块(如STM32),可以直接通过芯片内部模块输出PWM信号,直接配置一些值即可;若没有(如51)则可给I/O加一个定时器,对于你要求输出的PWM信号频率与你的定时器一致,用定时器中断来计数,但是这种方法一般不采用,除非对于精度、频率等要求不是很高可以这样实现。
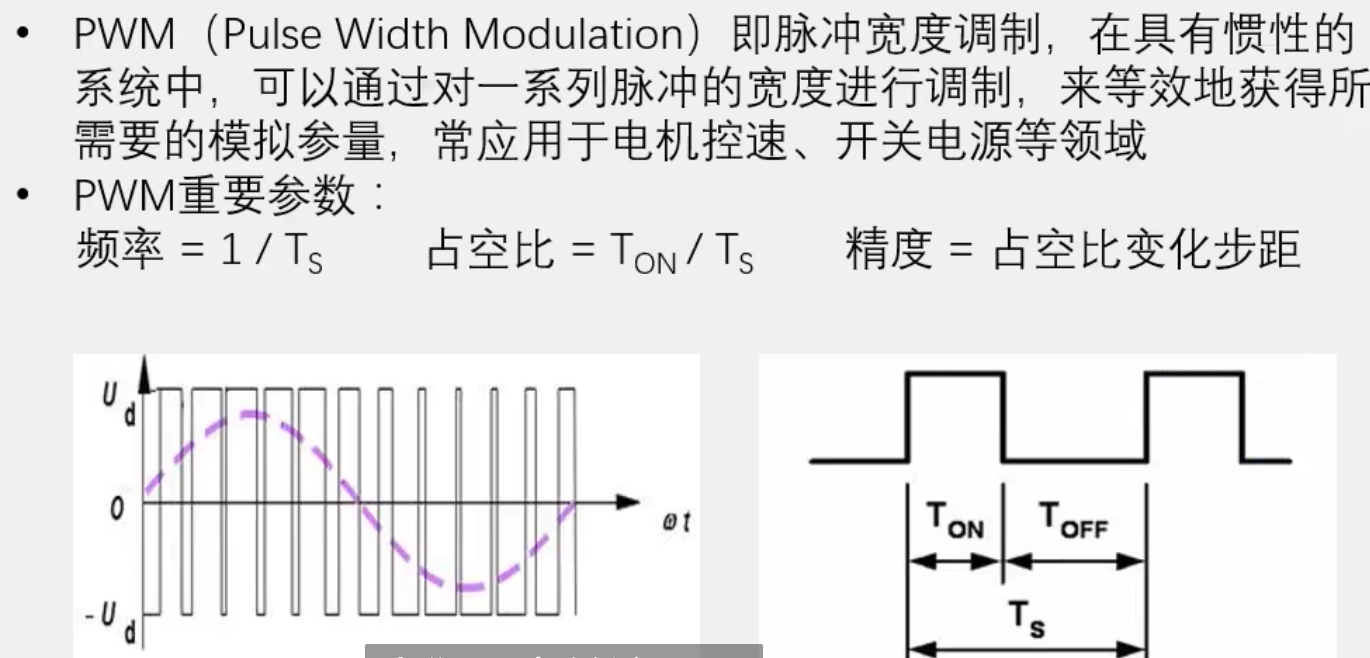
STM32输出PWM:
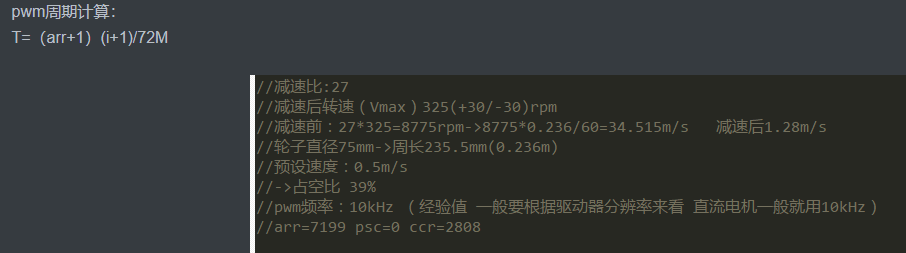
让计数器从0数到自动重装载值arr,arr其实就是定时器的一个周期。当计数值小于输出比较寄存器(ccr)时输出高电平,大于比较寄存器(ccr)时输出低电平。
单片机内部时钟经过分频(psc)后得到定时器时钟,修改psc即可修改计数器记数的速度,通过修改自动重装载值可以调节PWM的周期频率,修改比较寄存器的大小(ccr)可改变占空比。
PWM的频率 = 时钟频率 / (自动重装值arr + 1)*(预分频值psc + 1),STM32的最时钟频率为72MHz = 72 000 000 Hz
1 | /* |
在标准库里如下设置可配置arr和psc:
1 | TIM_TimeBaseInitStructure.TIM_Period=100 - 1; |
占空比 = CCR / (ARR + 1),当Compare = 50时,改PWM的占空比为50 / (100 - 1 + 1)=50%。
1 | TIM_SetCompare1(TIM2,Compare);//将Compare的值写入指定定时器的捕获/比较寄存器1(CCR1),用于设置PWM的比较值进而改变占空比 |
51单片机输出PWM:
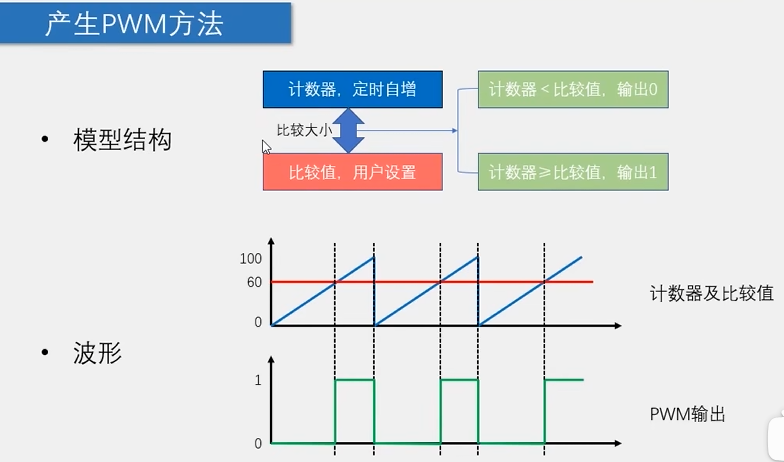
该结构与最新单片机TIM定时器PWM硬件结构相似,在这里我们用软件来模拟这一结构:
首先配置定时器,每100us进一次定时器中断,每次进入中断后计数器(Counter)+1,同时与比较值(Compare)比较,若Counter<Compare,置高电平,反之置低电平,在这里设置计数器最大到100后清0,pwm周期:100us*100=10ms ,若pwm频率过小则电机会出现抖动(频繁启动停止),故我们要让pwm频率取到一个相对大的值,这时就可等效的获得所需要的模拟参量
定时器的作用就在于生成周期为T,每个周期内高电平持续时间为Compare的波形.。
以下为51单片机驱动有刷直流电机的代码:
1 | //tim.c |
1 | //main.c |
舵机
舵机也叫也叫 RC 伺服器,通常用于机器人项目,也可以在遥控汽车,飞机等航模中找到它们。类似舵机这样的伺服系统通常由小型电动机,电位计,嵌入式控制系统和变速箱组成。电机输出轴的位置由内部电位计不断采样测量,并与微控制器(例如STM32,Arduino)设置的目标位置进行比较;根据相应的偏差,控制设备会调整电机输出轴的实际位置,使其与目标位置匹配,通过PWM向伺服器发送一个控制信号时,输出轴就可以转到特定的位置。只要控制信号持续不变,伺服机构就会保持相对的角度位置不变。如果控制信号发生变化,输出轴的位置也会相应发生变化。。这样就形成了闭环控制系统。


舵机上有三根线,分别是GND、VCC和PWM,也就是地线、电源线和信号线,其中的PWM波就是从信号线输入给舵机的。
驱动方法:一般来说,舵机接收的PWM信号频率为50HZ,即周期为20ms。当高电平的脉宽在0.5ms-2.5ms之间时舵机就可以对应旋转到不同的角度。
注意:不同类型和品牌的伺服电机之间最大位置和最小位置的角度可能会不同。许多伺服器仅旋转约170度(或者只有90度),但宽度为1.5 ms的伺服脉冲通常会将伺服设置为中间位置(通常是指定全范围的一半)
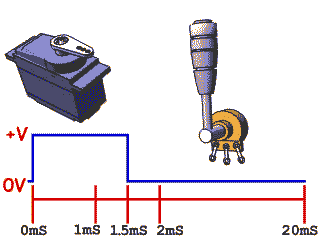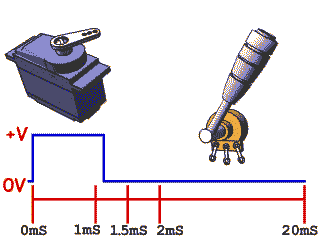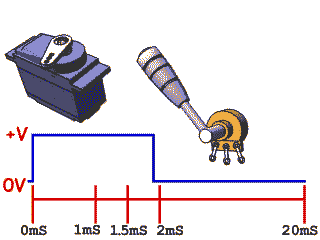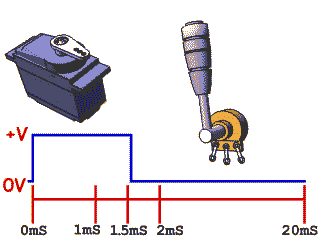
对于常见的SG90舵机,0-180°分别对应着500-2500us的高电平时长

1 | 占空比 = t / T 相关参数如下: |
STM32实现:
1.配置TIM定时器的周期为20ms(频率为50):
PWM的频率 = 时钟频率 / (自动重装值arr + 1)*(预分频值psc + 1),STM32的最时钟频率为72MHz = 72 000 000 Hz
1 | /* |
在标准库里如下设置:
1 | TIM_TimeBaseInitStructure.TIM_Period=100 - 1; |
2.占空比 = CCR / (ARR + 1),当Compare = 50时,改PWM的占空比为50 / (100 - 1 + 1)=50%。通过改变占空比即可改变舵机旋转的角度。
1 | TIM_SetCompare1(TIM2,Compare);//将Compare的值写入指定定时器的捕获/比较寄存器1(CCR1),用于设置PWM的比较值进而改变占空比 |
步进电机
步进电机, 故名思意,按步前进的电机,一般通过驱动器控制,因为配合驱动器可细分步长和调节电流,改变电机的输出功率,提高控制精度。其控制策略为,给予电机一个pwm脉冲,则旋转一步,我们选择的是42步电机,即旋转42步,电机转一圈。因此,给的pwm脉冲越多,电机可以转越多的步,可以转越大的角度,即pwm脉冲数可以控制电机旋转的角度;而pwm波的频率,即一个完整pwm脉冲所用的时间,对应转速,频率越快,一个完整pwm脉冲所用的时间越短,电机转速越快。
- 控制原理
通过 脉冲信号 控制步进角和转速,每个脉冲对应电机转动一个步距角(如1.8°/步)。- 需配合 相位顺序(如全步、半步、微步)驱动线圈。
- 驱动方式
- 必须外接 步进驱动器(如A4988、TMC2209)处理电流分配和细分控制。
- 控制信号包括脉冲(PUL)、方向(DIR)和使能(EN)。
- 特点
- 开环控制,依赖脉冲计数定位,无累积误差。
- 细分驱动可提高精度(如16细分下1.8°步距角变为0.1125°)。
- 低速扭矩大,但高速易失步,需合理选择驱动电流。
- 典型应用
3D打印机、CNC机床、精密仪器等需要高精度定位的场景。
直流有刷电机
- 控制原理
通过 电压极性 控制转向,电压幅值或PWM占空比 调节转速。 - 驱动方式
- 需使用 H桥电路(如L298N、TB6612)实现正反转和调速。
- PWM频率需匹配电机特性(通常1kHz~20kHz)。
- 特点
- 开环控制,无内置反馈,需外接编码器实现闭环。
- 结构简单、成本低,但电刷易磨损。
- 高速性能好,但低速扭矩较小。
- 典型应用
玩具车、风扇、无人机螺旋桨等需要连续旋转和调速的场景。
3D打印

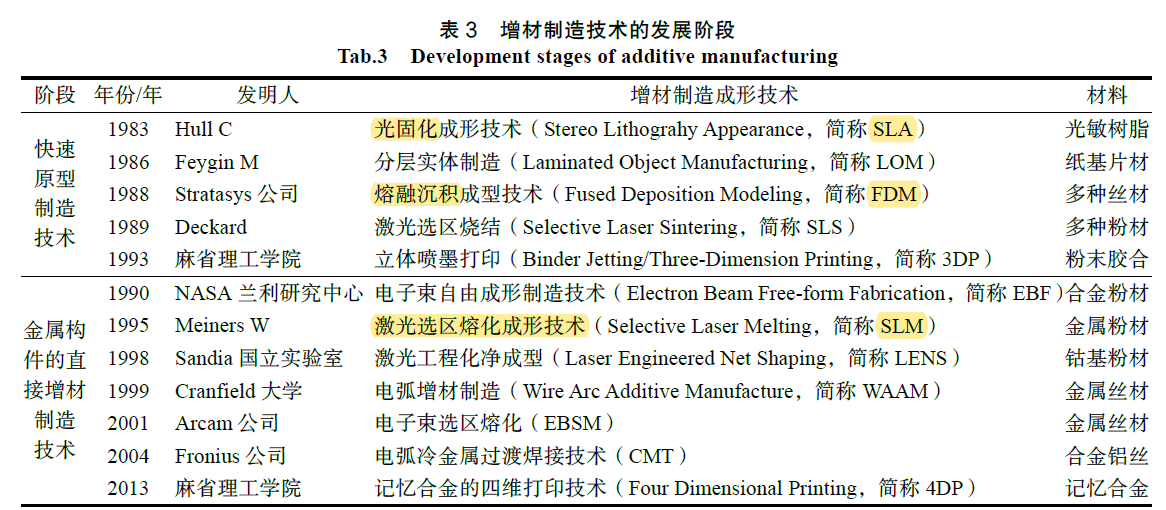
FDM(熔融沉积成型技术)&SLA(光固化成型技术)&SLM(激光烧结技术)
FDM(最广泛):
常见材料:
PLA,生物降解材料,环保无毒
ABS, 力学性能相对更好,抗冲击强度更高
FDM打印机操作简单,维护成本低
SLA
材料为光敏树脂
1. FDM(熔融沉积成型,Fused Deposition Modeling)
- 原理:通过加热喷嘴将热塑性材料(如PLA、ABS)熔融,逐层挤出堆积成型。
- 特点:
- 材料:低成本塑料线材,可选颜色丰富。
- 精度:较低(约±0.1-0.3mm),可见层纹。
- 速度:较慢,依赖模型大小和层高。
- 后处理:需去除支撑结构,表面需打磨。
- 优势:设备便宜(桌面级千元起)、操作简单、材料易获取。
- 局限:强度各向异性,细节表现差。
- 应用:原型验证、教育用途、简单功能件。
2. SLA(光固化成型,Stereolithography)
- 原理:紫外激光照射液态光敏树脂,逐层固化成型。
- 特点:
- 材料:光敏树脂(刚性、柔性、耐高温等种类)。
- 精度:极高(±0.05-0.1mm),表面光滑。
- 速度:较快,但后期需二次固化。
- 后处理:需酒精清洗、去除支撑,可能需UV固化。
- 优势:细节精细,适合复杂结构。
- 局限:树脂脆性大,长期可能发黄,设备较贵(工业级数万元起)。
- 应用:珠宝模具、牙科模型、高精度展示件。
3. SLM(选择性激光熔化,Selective Laser Melting)
- 原理:高能激光完全熔化金属粉末(如钛合金、不锈钢),逐层熔覆成型。
- 特点:
- 材料:金属粉末(钛、铝、钢等),需惰性气体保护。
- 精度:高(±0.05-0.1mm),接近锻造件强度。
- 速度:慢,需支撑结构防止变形。
- 后处理:去除支撑、热处理、机加工。
- 优势:直接制造致密金属件,力学性能优异。
- 局限:设备昂贵(百万级)、技术门槛高。
- 应用:航空航天零件、医疗植入物、汽车高性能部件。
对比总结
| 技术 | 材料类型 | 精度 | 强度 | 成本 | 典型应用 |
|---|---|---|---|---|---|
| FDM | 热塑性塑料 | 低 | 中等(各向异性) | 低 | 原型、教育模型 |
| SLA | 光敏树脂 | 极高 | 脆性 | 中高 | 精密零件、艺术品 |
| SLM | 金属粉末 | 高 | 极高(各向同性) | 极高 | 工业级功能金属件 |
选择建议:
快速验证/教育:选FDM。
高精度/美观需求:选SLA。
金属功能件:选SLM或类似金属打印技术(如DLMS)。

CAD关注的是几何上的建模方式,后者关注的是加工的工艺参数,机床几何和动力学


复试问题
起重机大赛经验贴:https://zhuanlan.zhihu.com/p/460393760
1.讲一下USART你是具体怎么用的
2.讲一下PID控制算法,你是怎么调试和优化PID参数的,遇到振荡、超调时你是怎么解决的
4.你每次是如何来选择合适的MCU作为项目的主控的
我最看重的一般是它的外设资源,比如定时器数量,因为电机控制,编码器等等需要用到定时器的数量比较多,所以对定时器数量需求大。也看应用场景,如果只是个小项目用c8t6就够用了
列出项目所需的外设接口(如GPIO、UART、SPI、I2C、ADC、PWM等),确保MCU支持这些功能。
评估程序代码大小、数据存储需求,确定所需的Flash和RAM容量。
C8T6 是 48 引脚,VET6 是 100 引脚,ZET6 是 144 引脚。引脚越多,可用的 GPIO 和外设资源越多。
STM32F103C8T6:价格最低,适合低成本项目。
STM32F103VET6:价格中等,性价比高。
STM32F103ZET6:价格较高,适合需要大量外设和引脚的项目
- STM32F103C8T6:
- Flash:64 KB
- RAM:20 KB
- STM32F103VET6:
- Flash:512 KB
- RAM:64 KB
- STM32F103ZET6:
- Flash:512 KB
- RAM:64 KB
C8T6 的存储资源较少,适合小型项目;VET6 和 ZET6 的 Flash 和 RAM 容量更大,适合更复杂的应用。
- STM32F103C8T6:
- 外设较少,适合简单应用。
- 例如:2 个 SPI、2 个 I2C、3 个 USART、1 个 USB、2 个 12 位 ADC(10 通道),4个定时器。
- STM32F103VET6:
- 外设更丰富。
- 例如:3 个 SPI、2 个 I2C、5 个 USART、1 个 USB、3个 12 位 ADC(16 通道), 8个定时器。
- STM32F103ZET6:
- 外设最丰富。
- 例如:3 个 SPI、2 个 I2C、5 个 USART、1 个 USB、3 个 12 位 ADC(21 通道),8个定时器。
5.在C语言进行嵌入式开发时,如何保证代码的可读性和可维护性
模块化封装,写好注释,变量起名字有实际意义最好为英文缩写。
6.驱动直流有刷电机时你是如何选择PWM的频率和占空比来满足需求,如何驱动步进电机以及舵机
步进电机, 故名思意,按步前进的电机,一般通过驱动器控制,因为配合驱动器可细分步长和调节电流,改变电机的输出功率,提高控制精度。其控制策略为,给予电机一个pwm脉冲,则旋转一步,我们选择的是42步电机,即旋转42步,电机转一圈。因此,给的pwm脉冲越多,电机可以转越多的步,可以转越大的角度,即pwm脉冲数可以控制电机旋转的角度;而pwm波的频率,即一个完整pwm脉冲所用的时间,对应转速,频率越快,一个完整pwm脉冲所用的时间越短,电机转速越快。
- 舵机(伺服电机)
- 控制原理
通过 PWM(脉宽调制)信号 控制角度,脉冲宽度决定位置(通常脉冲周期20ms,脉宽0.5ms2.5ms对应0°180°)。 - 驱动方式
- 直接输入PWM信号,无需外部驱动器(内部集成控制电路和减速齿轮)。
- 需要独立电源供电(大扭矩舵机需外接电源)。
- 特点
- 内置反馈(电位器或编码器),形成闭环控制,位置精度高。
- 输出扭矩大,但转动范围有限(通常0°~180°)。
- 典型应用
机器人关节、航模控制、摄像头云台等需要固定角度的场景。
- 步进电机
- 控制原理
通过 脉冲信号 控制步进角和转速,每个脉冲对应电机转动一个步距角(如1.8°/步)。- 需配合 相位顺序(如全步、半步、微步)驱动线圈。
- 驱动方式
- 必须外接 步进驱动器(如A4988、TMC2209)处理电流分配和细分控制。
- 控制信号包括脉冲(PUL)、方向(DIR)和使能(EN)。
- 特点
- 开环控制,依赖脉冲计数定位,无累积误差。
- 细分驱动可提高精度(如16细分下1.8°步距角变为0.1125°)。
- 低速扭矩大,但高速易失步,需合理选择驱动电流。
- 典型应用
3D打印机、CNC机床、精密仪器等需要高精度定位的场景。
- 直流有刷电机
- 控制原理
通过 电压极性 控制转向,电压幅值或PWM占空比 调节转速。 - 驱动方式
- 需使用 H桥电路(如L298N、TB6612)实现正反转和调速。
- PWM频率需匹配电机特性(通常1kHz~20kHz)。
- 特点
- 开环控制,无内置反馈,需外接编码器实现闭环。
- 结构简单、成本低,但电刷易磨损。
- 高速性能好,但低速扭矩较小。
- 典型应用
玩具车、风扇、无人机螺旋桨等需要连续旋转和调速的场景。
7.继电器,电磁阀,气泵是如何连接工作的****?(详见毕设)
对于继电器,电源线与继电器的公共端和常开引脚分别连接,未通电时不导通,当给其信号引脚发高电平时继电器的公共端与常开引脚吸合,电路导通,从而实现给用电器供电。
对于电磁阀和气泵,用一个两路继电器控制常开型二位三通电磁阀以及气泵,电磁阀断电,气泵通电时,气泵和吸盘所连接的两个气路是导通的,可以直接吸取物品,当对电磁阀通电时,吸盘所连接气路与电磁阀另一气路导通,与外界大气压直接接通,破坏了其真空环境从而释放箱体。
所谓常开两位三通电磁阀
- 两位:指阀芯有两个工作位置(例如通电/断电状态)。
- 三通:阀门有三个流体接口(通常标记为P-供压口、A-输出口、R-排气口)。
- 电磁阀:通过电磁线圈的通断电控制阀芯运动,从而切换流路。
- 常开:未通电时阀门打开,气泵与吸盘气路接通。
8.编码器你是如何使用的,它的工作原理是什么
使用增量式霍尔编码器,13线,4倍频,在一定周期内读取CNT值随后清0,累加可得到总脉冲数,可用于电机位置闭环控制。
工作原理:
9.麦克纳姆轮怎么安装的,怎么驱动它
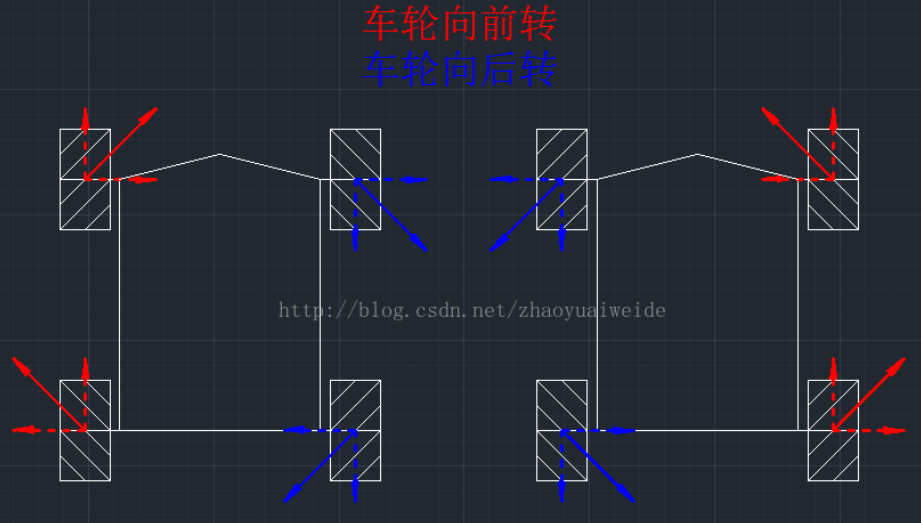
安装方式分为X型安装和O型安装,X型安装会导致旋转力矩很小或者无法旋转的情况发生,因此一般用O型安装。
前后行驶
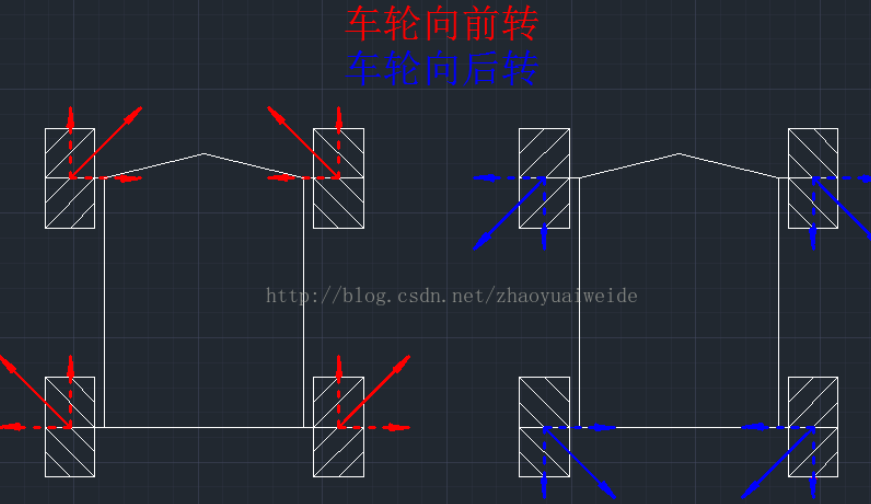
左右平移:
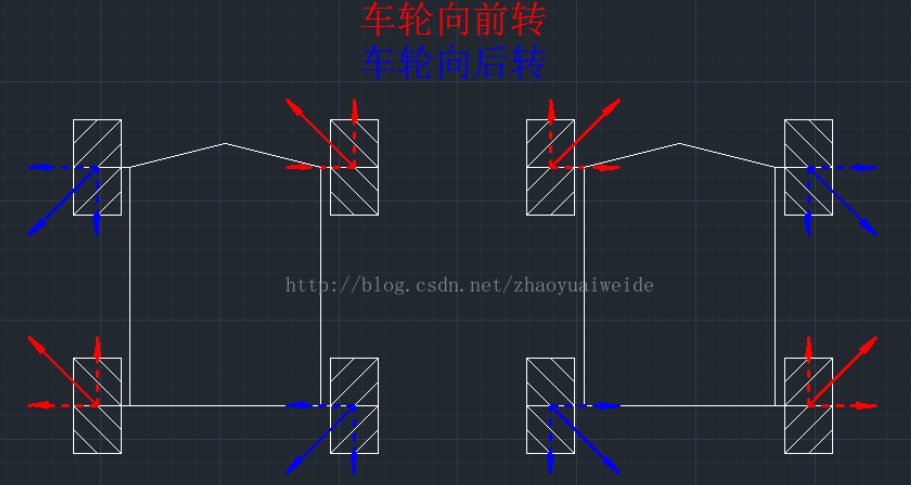
原地旋转:
10.你在项目中遇到的最大挑战是什么?怎么解决的?
11.你本科期间做了这么多比赛,你都学习到了什么东西?
 wechat
wechat alipay
alipay
